
L’essentiel à retenir : Mistral Small 4 unifie le raisonnement, la vision et le code au sein d’une architecture Mixture of Experts de 119 milliards de paramètres. Ce modèle polyvalent optimise les flux industriels en réduisant la latence de 40% par rapport à la version précédente. Sa fenêtre de contexte de 256 000 tokens permet l’analyse exhaustive de documents complexes. Pour en discuter directement: Contactez- nous!
Garantir la fiabilité du code généré par IA reste un défi majeur pour les développeurs face aux erreurs probabilistes des modèles classiques. Le lancement de Mistral Small 4 et le partenariat stratégique mistral ai nvidia apportent une réponse concrète via une architecture Mixture of Experts performante et l’agent de preuve formelle Leanstral. Vous découvrirez comment cette alliance optimise l’inférence sur GPU H100 tout en certifiant mathématiquement la justesse sous licence Apache 2.0.
Architecture et performances du modèle Mistral Small 4
Après des mois de rumeurs, l’annonce est tombée, et elle redéfinit ce qu’on attend d’un modèle de taille intermédiaire en termes de puissance brute et d’intelligence.
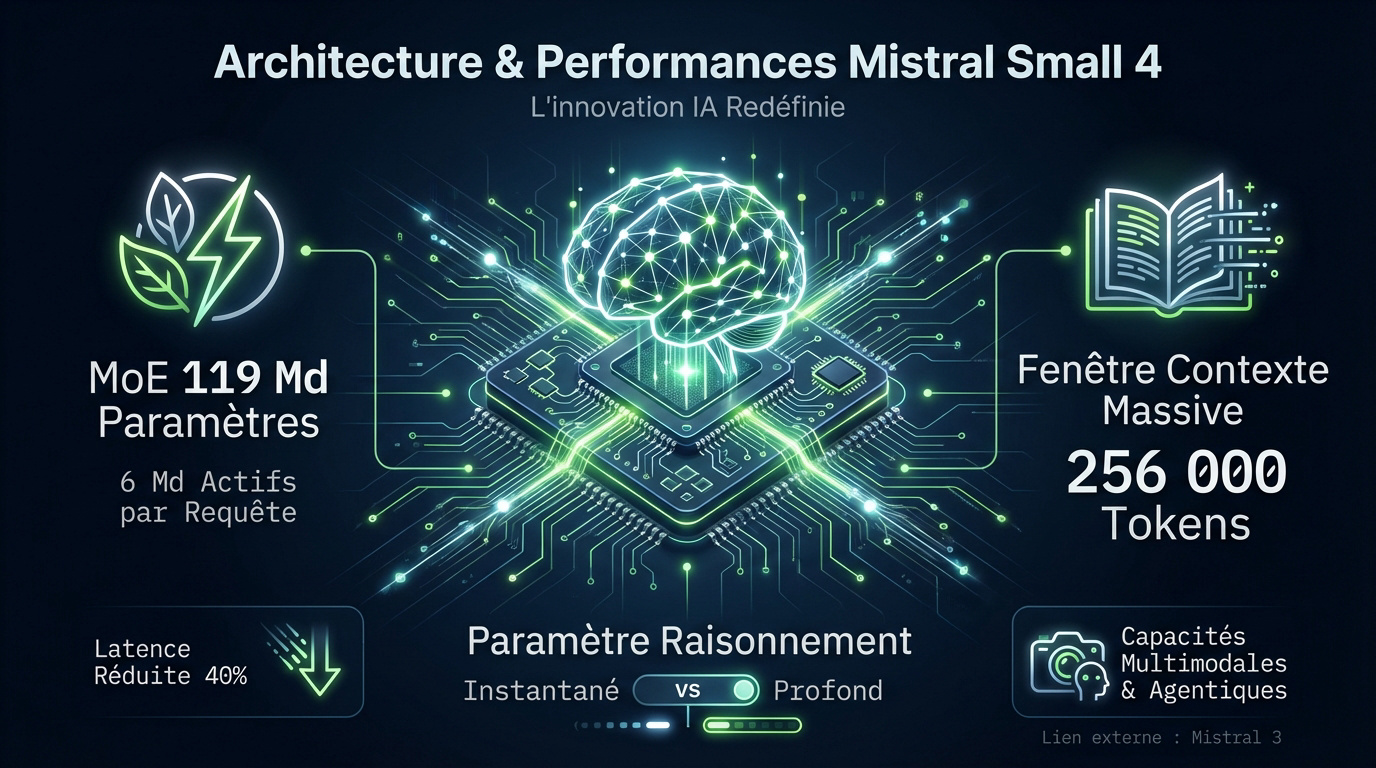
Efficacité du Mixture of Experts à 119 milliards de paramètres
Mistral Small 4 utilise une structure Sparse Mixture-of-Experts (MoE). Sur 119 milliards de paramètres totaux, seuls 6 milliards s’activent par requête. Cette architecture garantit une efficacité énergétique et une vitesse de traitement redoutables.
Le modèle intègre une fenêtre de contexte massive de 256 000 tokens. Cette capacité permet d’analyser des documents entiers ou des bases de code complexes. L’utilisateur traite des volumes de données importants sans perte de mémoire.
Un nouveau paramètre de raisonnement, nommé reasoning_effort, fait son apparition. L’utilisateur choisit entre une réponse instantanée ou une réflexion plus profonde. La vélocité s’ajuste ainsi précisément.
Unification des capacités multimodales et agentiques native
Ce moteur unique fusionne les lignées Pixtral pour la vision et Devstral pour le code. Il traite désormais nativement les images et le texte. Aucun module externe n’est requis pour ces tâches complexes.
Les gains de performance sont concrets pour les développeurs. La latence diminue de 40% par rapport à la version Small 3. Les interactions deviennent beaucoup plus fluides et rapides pour l’utilisateur final.
En entreprise, ce modèle facilite l’automatisation des workflows complexes. Les nouvelles capacités multimodales de la nouvelle génération optimisent l’analyse de documents et la gestion autonome des tâches de programmation.
Alliance Mistral AI et NVIDIA au sein de la coalition Nemotron
Cette prouesse technique ne sort pas de nulle part ; elle s’appuie sur une alliance musclée avec le géant des puces, changeant la donne géopolitique de l’IA.
Mutualisation des ressources de calcul et accès au cloud DGX
Mistral AI entraîne le futur modèle Nemotron 4. L’entreprise utilise massivement les infrastructures NVIDIA. Cette collaboration vise une puissance de calcul inédite pour les acteurs européens.
Les conteneurs NVIDIA NIM facilitent le déploiement local. Les entreprises protègent ainsi leurs données sensibles. Aucun flux ne s’échappe vers le cloud public durant l’exécution des modèles.
L’usage de données synthétiques optimise l’apprentissage. Les GPU H100 propulsent l’entraînement de Mistral NeMo. Ce processus garantit des performances de haute volée pour les LLMs.
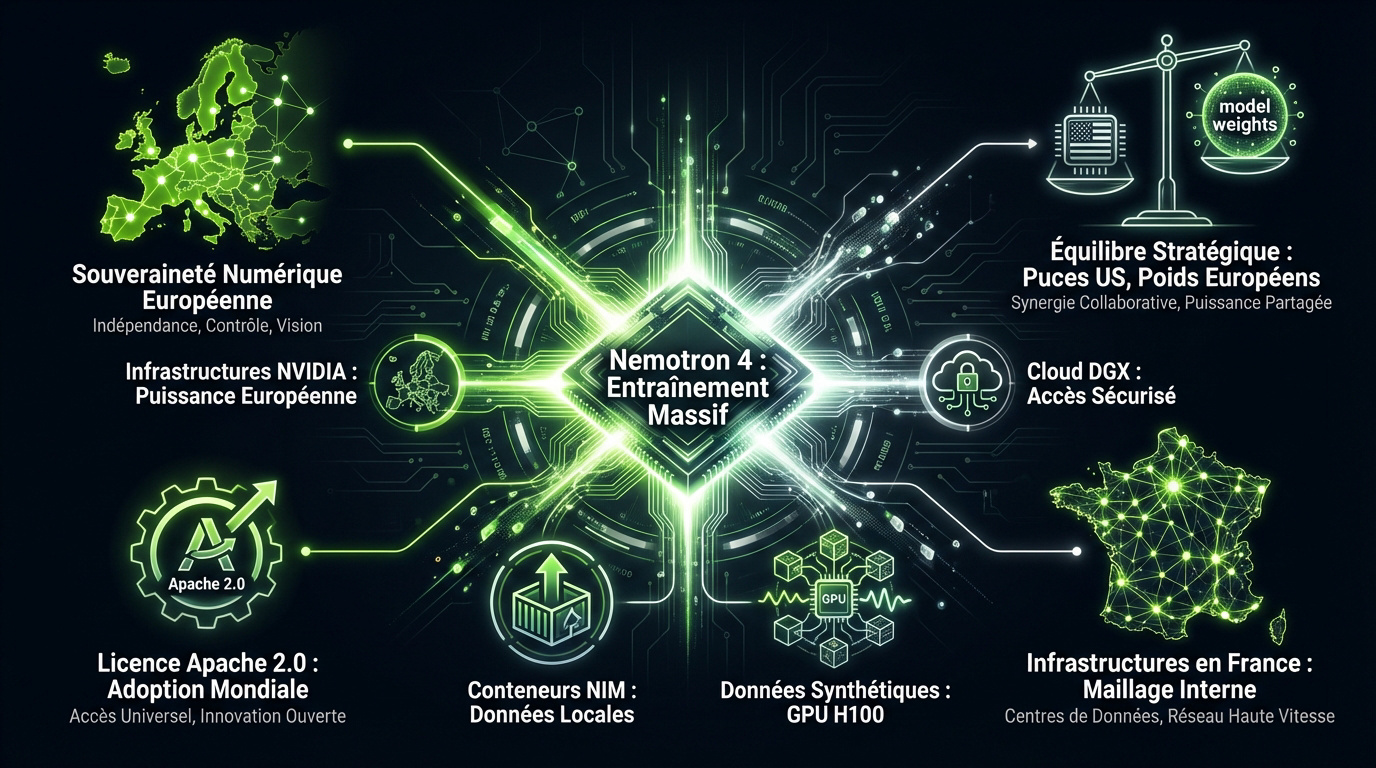
Souveraineté numérique face aux régulations extra-territoriales
Mistral AI exploite des puces américaines avec pragmatisme. La startup conserve le contrôle total des poids de ses modèles. Cette stratégie préserve l’autonomie décisionnelle de l’industrie européenne.
La licence Apache 2.0 encourage une diffusion large. Elle empêche le verrouillage technologique par des systèmes propriétaires fermés. L’adoption mondiale des modèles ouverts s’en trouve ainsi accélérée.
L’entreprise développe ses propres centres de données en France. Ce maillage renforce la Mistral AI : le Mbappé de l’intelligence artificielle – Uplix souveraineté. La conformité aux régulations européennes reste une priorité absolue.
Sécurisation du code via l’agent de preuve formelle Leanstral
Mais la vraie rupture ne se limite pas à la puissance ; elle réside dans la capacité de l’IA à prouver mathématiquement qu’elle ne se trompe pas.
Fiabilité mathématique du code généré avec Lean 4
Le passage à la certification formelle marque un tournant majeur. Contrairement aux IA classiques qui devinent, Leanstral utilise la logique mathématique pour valider chaque ligne de code produite.
Cet agent spécialisé mobilise 6 milliards de paramètres actifs. Il ne se contente pas d’écrire du code, il vérifie sa justesse absolue via le langage de preuve Lean 4.
La preuve formelle transforme l’IA générative d’un outil de suggestion en un système de production critique, où l’erreur n’est plus une fatalité statistique mais un problème résolu.
Analyse du rapport performance-coût face aux modèles propriétaires
Sur le benchmark FLTEval, Leanstral affiche des scores impressionnants. Il surpasse souvent des modèles massifs comme Claude 4.6 sur des tâches de logique pure. La spécialisation bat ici la force brute.
L’économie réalisée est massive pour les entreprises. Utiliser ce modèle de 6 milliards de paramètres coûte une fraction du prix d’un modèle géant pour des résultats supérieurs en codage.
L’outil excelle en mathématiques et en programmation. Pourtant, il reste moins polyvalent que ses concurrents pour la rédaction créative ou les tâches généralistes.
Déploiement industriel et trajectoire stratégique européenne
Au-delà des laboratoires, c’est sur le terrain de l’industrie et de l’écologie que se joue désormais la pérennité de ce modèle européen.
Intégration logicielle et optimisation de la latence sur site
Le modèle assure une compatibilité native avec vLLM et SGLang. Ces frameworks garantissent une inférence ultra-rapide. C’est un prérequis vital pour les systèmes industriels réagissant en temps réel.
L’accès aux modèles ouverts favorise une adoption large par les entreprises. Cette stratégie limite la IA génératives en 2025 : « révolution créative » ou « fracture numérique … en démocratisant les technologies de pointe. La flexibilité technique devient alors un avantage compétitif majeur.
Les organisations disposent de plusieurs canaux pour exploiter ces capacités :
- API La Plateforme pour une intégration simplifiée.
- Déploiement via Azure AI pour les environnements cloud.
- Intégration native dans NVIDIA AI Enterprise pour les infrastructures privées.
Maîtrise de l’empreinte carbone via les data centers locaux
L’architecture Mixture of Experts (MoE) réduit les paramètres actifs par requête. Cela limite les cycles GPU nécessaires. La consommation électrique et les coûts opérationnels diminuent ainsi mécaniquement.
Le recours à des infrastructures régionales renforce la souveraineté des données. Le projet de campus IA d’Europe illustre cette volonté de bâtir une puissance de calcul locale et durable.
Mistral projette d’atteindre un milliard d’euros de revenus en 2026. Cette rentabilité prouve qu’un champion européen peut rivaliser avec les géants américains. Pour en discuter directement: Contactez- nous!.
L’alliance entre Mistral AI et NVIDIA propulse l’IA européenne vers une efficacité inédite. Avec le modèle Small 4 et l’agent Leanstral, vous accédez dès maintenant à une puissance de calcul souveraine et certifiée. Adoptez ces technologies ouvertes pour transformer radicalement votre productivité industrielle et sécuriser votre avenir numérique.
FAQ
Quelles sont les caractéristiques techniques du nouveau modèle Mistral Small 4 ?
Mistral Small 4 est un modèle polyvalent qui unifie le raisonnement, la vision (multimodalité) et le code agentique. Il remplace les anciens modèles spécialisés comme Pixtral ou Devstral par une architecture unique et performante.
Ce modèle utilise une structure Mixture of Experts (MoE) de 119 milliards de paramètres, dont seulement 6 milliards sont actifs par requête. Il dispose d’une fenêtre de contexte de 256 000 tokens et d’un paramètre reasoning_effort pour ajuster la profondeur de l’analyse.
En quoi consiste l’alliance stratégique entre Mistral AI et NVIDIA ?
Mistral AI est membre fondateur de la Coalition Nemotron aux côtés de NVIDIA. Ce partenariat vise à co-développer Nemotron 4, un modèle de base open source entraîné sur l’infrastructure NVIDIA DGX Cloud.
Cette collaboration permet à Mistral AI d’accéder à une puissance de calcul massive, incluant des GPU H100 et B200. L’objectif est de structurer l’écosystème open source face aux modèles propriétaires tout en garantissant une optimisation native pour le matériel NVIDIA.
Qu’est-ce que l’agent Leanstral et quel est son rôle dans la preuve formelle ?
Leanstral est le premier agent open source de 6 milliards de paramètres dédié à la preuve formelle avec le langage Lean 4. Contrairement aux IA probabilistes, il génère des démonstrations mathématiques pour certifier la correction du code produit.
Sur le benchmark FLTEval, Leanstral surpasse des modèles comme Claude 4.6 en termes de rapport performance-coût pour les tâches logiques. Il transforme l’IA générative en un système de production critique où la justesse du code est vérifiée mathématiquement.
Comment déployer les solutions de Mistral AI en entreprise ?
Les modèles comme Mistral Small 4 sont disponibles via l’API La Plateforme, sur Hugging Face ou via Azure AI. Ils sont également proposés sous forme de conteneurs NVIDIA NIM pour un déploiement sécurisé sur site (on-premise).
Grâce à la licence Apache 2.0, les organisations bénéficient d’une flexibilité totale pour l’intégration. L’utilisation de frameworks comme vLLM ou SGLang assure une latence réduite et une efficacité maximale pour les applications industrielles en temps réel.
Quel est l’impact de ces annonces sur la souveraineté numérique européenne ?
Mistral AI renforce l’autonomie technologique de l’Europe en maintenant le contrôle sur les poids de ses modèles et en investissant dans des centres de données locaux, notamment en France et en Suède. L’efficacité de l’architecture MoE réduit également l’empreinte carbone liée au calcul.
L’entreprise française vise un chiffre d’affaires d’un milliard d’euros, prouvant la viabilité économique d’un acteur souverain. Cette stratégie permet de répondre aux exigences de sécurité des institutions, comme le ministère des Armées, tout en utilisant des infrastructures de pointe.



