
L’essentiel à retenir : Google révolutionne les systèmes de recommandation en inversant les Concept Activation Vectors (CAVs) pour décoder la subjectivité humaine. Cette méthode traduit les attributs « doux » en vecteurs mathématiques, permettant de saisir l’intention sémantique personnalisée au-delà des simples clics. Validée via l’algorithme WALS, cette approche optimise le ciblage grâce au few-shot learning sans réentraînement complet.
Pourquoi les algorithmes de recommandation échouent-ils à saisir la subjectivité des préférences utilisateurs, un enjeu central pour les concept activation vectors google ? Une récente publication technique détaille comment l’inversion de ces vecteurs permet désormais de traduire l’intention sémantique personnalisée en représentations mathématiques exploitables par les LLM. Cette analyse examine le mécanisme de cette détection vectorielle et ses répercussions concrètes sur l’optimisation du filtrage collaboratif et la précision du référencement.
Les concept activation vectors : la base de l’interprétabilité IA
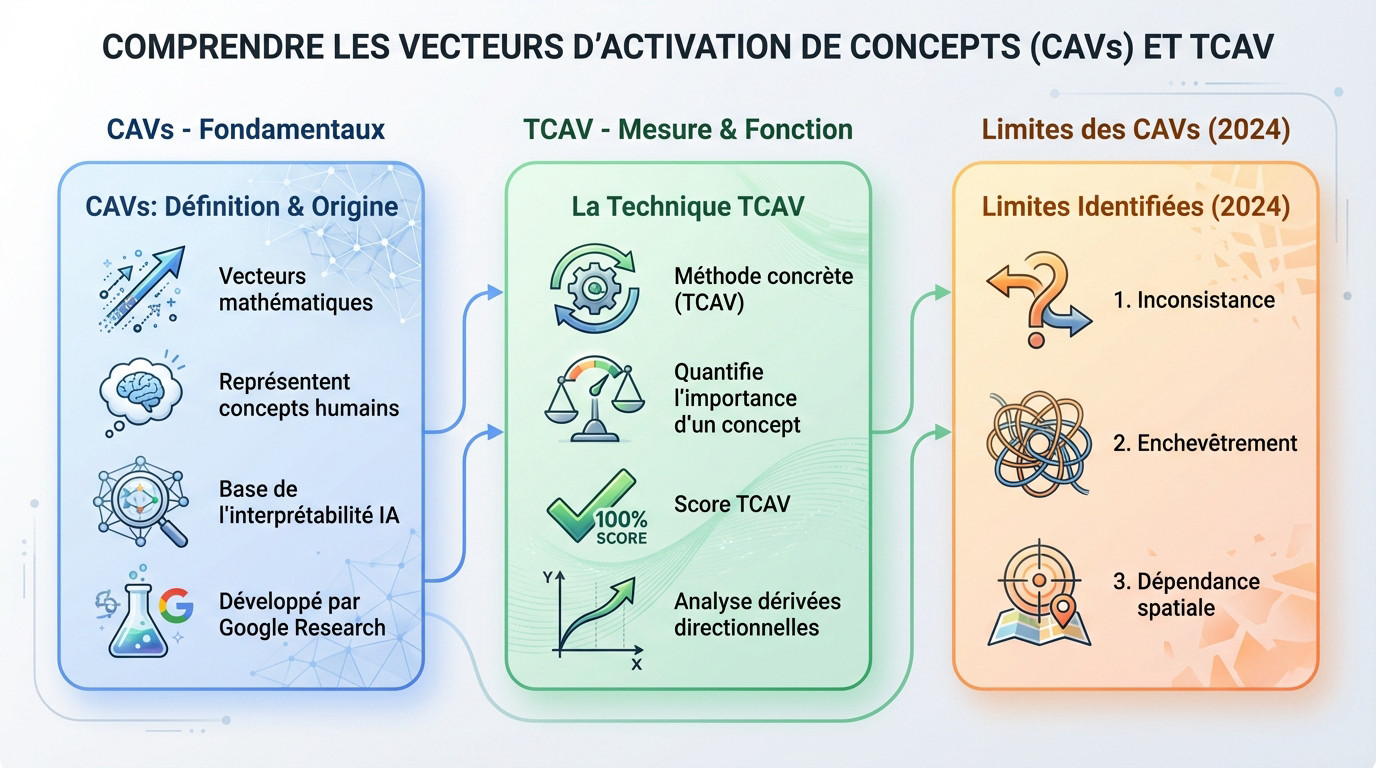
Définition et origine des CAVs
Les Concept Activation Vectors (CAVs) sont des vecteurs mathématiques. Ils représentent des concepts compréhensibles par l’humain dans un modèle d’IA. Ces vecteurs traduisent la complexité interne en signaux clairs.
Leur fonction première est de mesurer la sensibilité d’un réseau de neurones à un concept spécifique. Par exemple, la présence de « rayures » pour identifier un « zèbre ». C’est une méthode d’interprétabilité précise.
Google a réalisé une avancée majeure dans les systèmes de recommandation. Cette approche, détaillée dans un article de 2024, utilise les CAVs pour détecter l’intention sémantique personnalisée des utilisateurs.
Le rôle de la technique TCAV
TCAV (Testing with Concept Activation Vectors) est la méthode concrète qui utilise les CAVs. Elle quantifie l’importance d’un concept pour une prédiction donnée. Le score TCAV indique cette importance avec une précision mathématique rigoureuse pour l’analyse.
TCAV analyse les dérivées directionnelles dans l’espace d’activation du modèle. Cela révèle comment le modèle réagit à la présence ou l’absence d’un concept. Cette analyse permet de comprendre la logique interne sans ambiguïté.
Les limites identifiées des CAVs classiques
Les recherches récentes de 2024 ont mis en lumière certaines propriétés complexes. Ces facteurs techniques peuvent parfois limiter la fiabilité des vecteurs d’activation dans des contextes spécifiques.
- L’inconsistance : les CAVs varient de manière significative entre les différentes couches du réseau neuronal.
- L’enchevêtrement : un seul CAV peut coder plusieurs concepts distincts, rendant l’interprétation confuse.
- La dépendance spatiale : la position exacte du concept dans une image influence fortement la détection.
Le mur de la subjectivité dans les recommandations actuelles
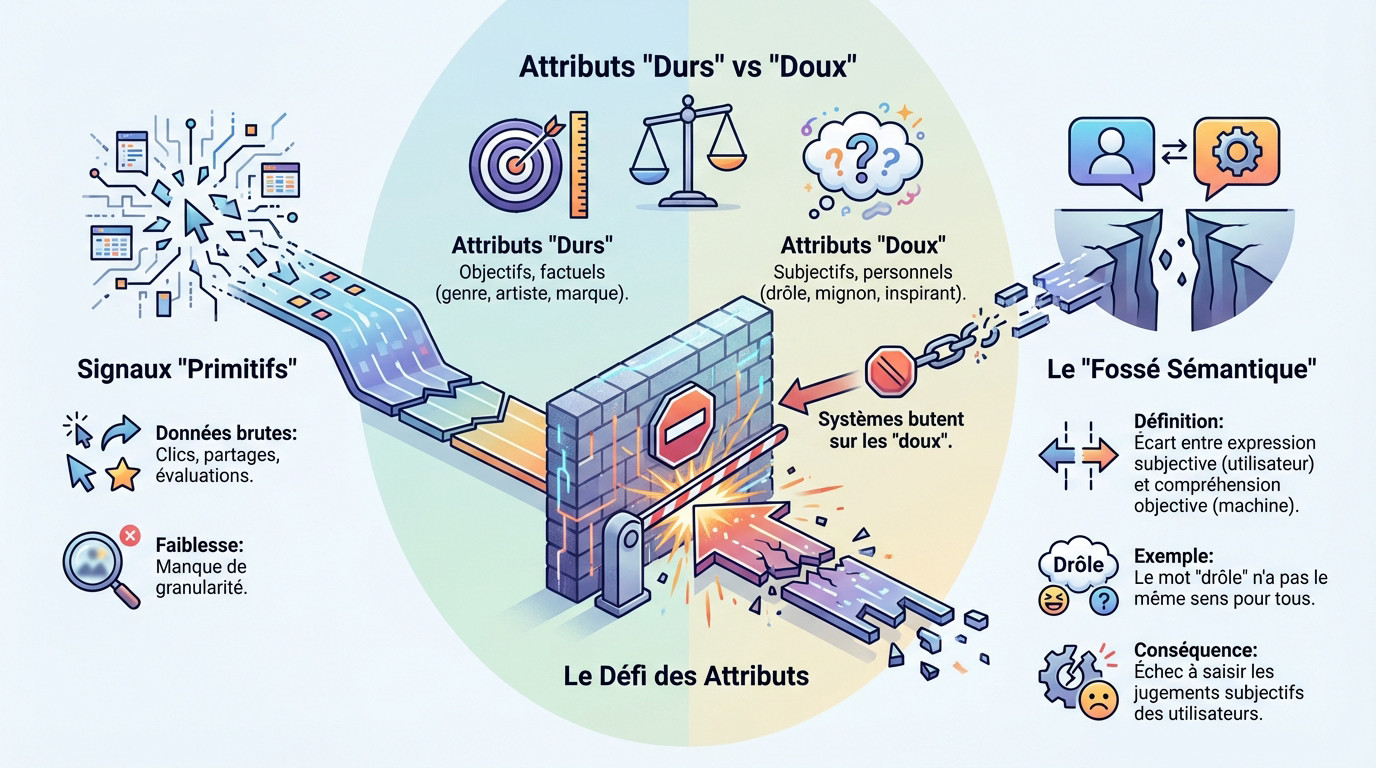
Les signaux « primitifs » et leurs faiblesses
Les architectures de recommandation historiques, telles que celles de YouTube ou Google News, fonctionnent sur une mécanique d’ingestion de données brutes. Elles opèrent sans la finesse d’analyse qu’apportent désormais les concept activation vectors Google.
Google qualifie ces indicateurs historiques de signaux « primitifs ». Il s’agit concrètement des clics, des partages ou des évaluations par étoiles qui alimentent les boucles de rétroaction.
La faiblesse structurelle de ces signaux réside dans leur manque de granularité. Ils échouent systématiquement à capturer la raison profonde ou l’émotion spécifique qui déclenche l’interaction de l’utilisateur avec un contenu.
Le défi des attributs « doux » et « durs »
Pour affiner la pertinence, les chercheurs de Google introduisent une distinction sémantique nette entre deux types d’attributs pour qualifier un contenu. Cette classification vise à isoler la subjectivité.
- Les attributs « durs » correspondent aux données objectives et factuelles, immédiatement identifiables par la machine, comme le genre, l’artiste ou la marque.
- Les attributs « doux » désignent les perceptions subjectives et personnels, tels que « drôle », « mignon », « inspirant » ou « effrayant ». C’est sur ces derniers que les systèmes butent.
Le « fossé sémantique » personnalisé
Le « fossé sémantique » matérialise l’écart technique entre ce qu’un utilisateur exprime subjectivement et ce que la machine comprend objectivement. Un adjectif comme « drôle » ne possède pas la même définition pour tout le monde.
Les systèmes de recommandation actuels échouent à saisir les jugements subjectifs des utilisateurs, se contentant de données brutes comme les clics, incapables de différencier une appréciation objective d’une préférence personnelle.
L’approche de Google : inverser la machine pour décoder l’humain
Google a réalisé une avancée majeure dans les systèmes de recommandation, permettant de détecter l’intention sémantique personnalisée des utilisateurs grâce à une nouvelle approche basée sur les Concept Activation Vectors (CAVs), comme détaillé dans un article de recherche publié en 2024. Cette méthode détourne l’usage premier des vecteurs. C’est le point central de l’avancée.
L’idée est de retourner l’outil : au lieu d’utiliser les CAVs pour interpréter le modèle, nous les utilisons pour interpréter l’utilisateur et traduire sa sémantique personnelle en une représentation mathématique.
Traduire l’intention sémantique en vecteurs
Le système apprend ce que « mignon » ou « drôle » signifie pour un utilisateur spécifique. Il traduit cette intention sémantique personnalisée en un vecteur. Ce vecteur est unique à chaque utilisateur. L’analyse des `concept activation vectors google` valide ce mécanisme précis.
Cela permet au modèle d’IA de détecter des intentions subtiles. Il peut ainsi différencier l’usage objectif et subjectif des tags et des descriptions. La pertinence des suggestions augmente mécaniquement.
Le rôle des grands modèles linguistiques (LLM)
L’essor des grands modèles linguistiques (LLM) a rendu cette approche possible. Leur capacité à comprendre le langage naturel est fondamentale. Sans cette brique technologique, l’analyse échouerait.
Les LLM aident à interpréter les descriptions en langage naturel des utilisateurs. Ils fournissent la base sémantique sur laquelle les CAVs peuvent ensuite travailler. Le système gagne alors en finesse d’interprétation.
Avantages et fonctionnement d’un système sémantique personnalisé
Cette méthode innovante utilisant les concept activation vectors Google se traduit par des bénéfices concrets et s’intègre aux architectures existantes.
Les quatre bénéfices majeurs de l’approche
La recherche de Google met en avant quatre avantages principaux pour cette méthode d’analyse. Elle optimise radicalement la gestion technique des recommandations.
- Le modèle se concentre sur la prédiction des préférences utilisateur-élément sans traiter d’informations secondaires parasites.
- De nouveaux attributs peuvent être ajoutés sans réentraînement complet de l’architecture globale.
- Il est possible de tester la pertinence de chaque attribut doux pour valider son impact réel.
- L’apprentissage se fait avec peu de données étiquetées grâce à la technique du few-shot learning.
Intégration avec le filtrage collaboratif
Le système fonctionne techniquement en s’appliquant sur un modèle de filtrage collaboratif existant. L’exemple technique repose sur la factorisation matricielle probabiliste. Les utilisateurs et les éléments sont projetés dans un espace latent commun. Cette structure mathématique organise les données.
Les CAVs agissent ici comme des sondes pour analyser cet espace vectoriel. Ils vérifient si le modèle a bien appris une représentation de l’attribut subjectif pour un utilisateur donné. Cette étape valide l’interprétation sémantique.
Un apprentissage basé sur peu de données
Le système n’a besoin que d’un petit ensemble de tags d’attributs doux pour démarrer efficacement. Cette exigence réduite simplifie le déploiement initial.
L’utilisation du « few-shot learning » rend le système plus agile et moins coûteux en ressources de calcul. Il n’est pas nécessaire d’avoir des millions d’exemples pour chaque concept subjectif. L’efficacité prime sur le volume.
Validation technique et implications pour l’écosystème Google
Au-delà de la théorie, Google a déjà validé cette approche sur des systèmes concrets, ce qui laisse entrevoir des applications futures directes.
Tests et validation sur des jeux de données publics
Google a réalisé une avancée majeure dans les systèmes de recommandation en testant cette méthode avec l’algorithme WALS. Ce système de moindres carrés alternés pondérés provient directement de Google Cloud. L’intégration technique ne nécessite pas de refonte complète.
Les ingénieurs ont validé le modèle sur le jeu de données public MovieLens20M ainsi que sur leur moteur propriétaire. Cette double vérification prouve la robustesse du système face à des volumes massifs. L’applicabilité en production semble donc immédiate et efficace.
Impact potentiel sur Google Discover et le SEO
Cette technologie cible potentiellement des systèmes comme Google Discover, bien que cela reste officieux. La pertinence des flux d’actualités augmenterait alors de façon spectaculaire. La personnalisation quitte le stade des clics pour devenir réellement sémantique. Chaque utilisateur reçoit enfin ce qu’il attend vraiment.
Pour les éditeurs, saisir l’intention subjective devient une priorité absolue. Ignorer ce changement risque de rendre les contenus invisibles face aux algorithmes modernes. Il faut désormais surveiller les nouvelles tendances SEO qui privilégient le sens.
Une recherche collaborative
Cette innovation ne résulte pas uniquement des laboratoires de Mountain View. L’effort scientifique implique plusieurs acteurs majeurs du numérique.
- La majorité du travail provient de Google Research, à hauteur de 60%.
- Des chercheurs d’Amazon et de Midjourney ont également participé.
- L’équipe inclut enfin des experts de Meta AI, montrant un intérêt partagé.
L’utilisation inversée des Concept Activation Vectors marque une rupture technologique majeure pour les systèmes de recommandation. En décodant les attributs subjectifs via les LLMs, Google dépasse les simples signaux comportementaux. Cette transition vers une sémantique personnalisée impose aux experts SEO d’optimiser les contenus pour l’intention utilisateur réelle plutôt que pour des mots-clés isolés.
FAQ
Qu’est-ce qu’un Concept Activation Vector (CAV) ?
Les Concept Activation Vectors (CAVs) sont des vecteurs mathématiques qui traduisent des concepts humains compréhensibles en représentations internes pour un modèle d’intelligence artificielle. Ils permettent de mesurer la sensibilité d’un réseau de neurones à un concept spécifique, comme une texture ou une émotion.
Développée par Google Research, cette méthode vise initialement à l’interprétabilité des modèles d’apprentissage automatique. Elle transforme les processus opaques des « boîtes noires » en données explicables et quantifiables.
Comment Google utilise-t-il les CAVs pour la recommandation ?
Dans ses recherches de 2024, Google inverse l’usage traditionnel des CAVs pour interpréter l’utilisateur plutôt que le modèle. Le système traduit l’intention sémantique personnelle d’un individu en un vecteur mathématique unique.
Cette approche permet au système de recommandation de comprendre des nuances subjectives. L’algorithme détecte ainsi ce qu’un utilisateur spécifique entend réellement par des termes vagues ou qualitatifs.
Quelle est la différence entre attributs « durs » et « doux » ?
Les attributs « durs » désignent des données objectives et factuelles, telles que le genre d’un film, l’auteur d’un livre ou la durée d’une vidéo. Ils ne sont pas sujets à interprétation et constituent la base des systèmes classiques.
À l’inverse, les attributs « doux » représentent des concepts subjectifs comme « drôle », « mignon » ou « inspirant ». Ces qualificatifs varient selon la perception de chaque utilisateur et nécessitent une analyse sémantique personnalisée par les CAVs.
En quoi consiste le problème du « fossé sémantique » ?
Le fossé sémantique désigne l’écart entre l’expression subjective d’un utilisateur en langage naturel et la compréhension objective de la machine. Les signaux primitifs comme les clics ne suffisent pas à capturer cette dimension.
L’utilisation des CAVs vise à combler ce fossé. Elle permet de modéliser mathématiquement des préférences abstraites pour aligner les recommandations sur l’intention réelle de l’internaute.
Quel est le rôle des LLM dans cette architecture ?
Les grands modèles linguistiques (LLM) apportent la capacité de traitement du langage naturel nécessaire à cette méthode. Ils analysent les descriptions et les tags fournis par les utilisateurs pour en extraire le sens.
Cette base sémantique est ensuite exploitée par les CAVs. Le système combine ainsi la puissance linguistique des LLM avec la précision vectorielle pour affiner le filtrage collaboratif.
Quel impact cette technologie peut-elle avoir sur le SEO ?
L’application de cette méthode à des plateformes comme Google Discover pourrait modifier les critères de pertinence. L’algorithme privilégierait davantage l’adéquation avec l’intention sémantique subjective que la simple correspondance de mots-clés.
Pour les stratégies SEO, cela implique une focalisation accrue sur la qualification précise du contenu. La compréhension des attributs « doux » devient un levier pour toucher des audiences aux préférences spécifiques.



