

L’essentiel à retenir : Google traite la canonicalisation lors du crawl du HTML brut et après l’exécution du JavaScript. Une incohérence entre ces deux versions provoque des signaux contradictoires nuisibles à l’indexation. La stratégie gagnante impose une correspondance exacte de l’URL canonique avant et après le rendu, ou son absence totale dans le code source initial.
Les conflits de canonicalisation entre le code serveur et le rendu client perturbent l’indexation, imposant une rigueur accrue sur la google javascript seo url. La documentation mise à jour formalise le double processus d’analyse du moteur et précise les standards de consolidation des pages dupliquées. Cette synthèse technique présente les configurations requises pour aligner les signaux et garantir la prise en compte exacte des directives par les robots d’exploration.
Google et JavaScript : la nouvelle donne pour les url canoniques
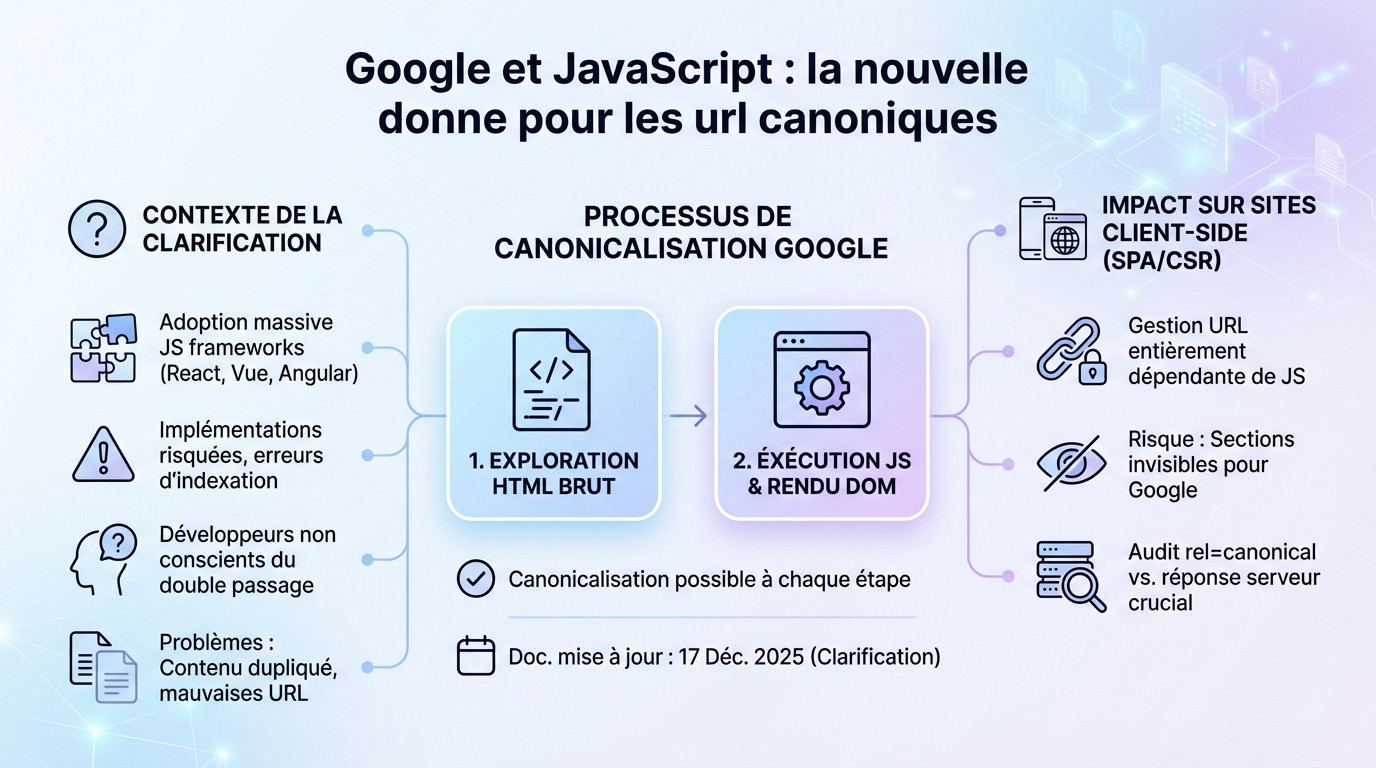
Le double processus de canonicalisation de Google
Google traite les pages JS en deux temps distincts. Le moteur explore d’abord le HTML brut transmis par le serveur. Ensuite, il exécute le code JavaScript pour obtenir le DOM rendu final.
La canonicalisation peut survenir à chacune de ces deux étapes critiques. deux étapes critiques
Cette mise à jour de la documentation, datée du 17 décembre 2025, ne change pas le comportement de Google mais le clarifie. C’est une formalisation technique de pratiques existantes souvent mal interprétées.
Pourquoi cette clarification arrive maintenant ?
L’adoption massive des frameworks JavaScript comme React ou Vue a multiplié les cas d’implémentations hasardeuses. Google a donc jugé nécessaire de fournir des directives claires pour éviter les erreurs d’indexation généralisées sur le web.
De nombreux développeurs n’avaient pas conscience de ce double passage obligatoire. Les problèmes de contenu dupliqué ou de mauvaise URL indexée étaient souvent mal diagnostiqués par les équipes.
Le sujet du SEO pour JavaScript est complexe, et cette clarification vise à guider les équipes techniques.
L’impact direct sur les sites en rendu côté client
Pour les Single Page Applications (SPA) et les sites basés sur le rendu côté client, cette directive est fondamentale. La gestion des URL et du google javascript seo url dépend entièrement du script.
Une mauvaise gestion des balises canoniques peut rendre des sections entières d’un site invisibles pour Google. Le risque de perte de trafic est donc majeur pour ces plateformes.
Les équipes doivent désormais auditer la manière dont leur framework JS interagit avec les balises `rel= »canonical »`. Il faut s’assurer que le code côté client ne crée pas de conflit avec la réponse initiale du serveur.
Le casse-tête des signaux canoniques contradictoires
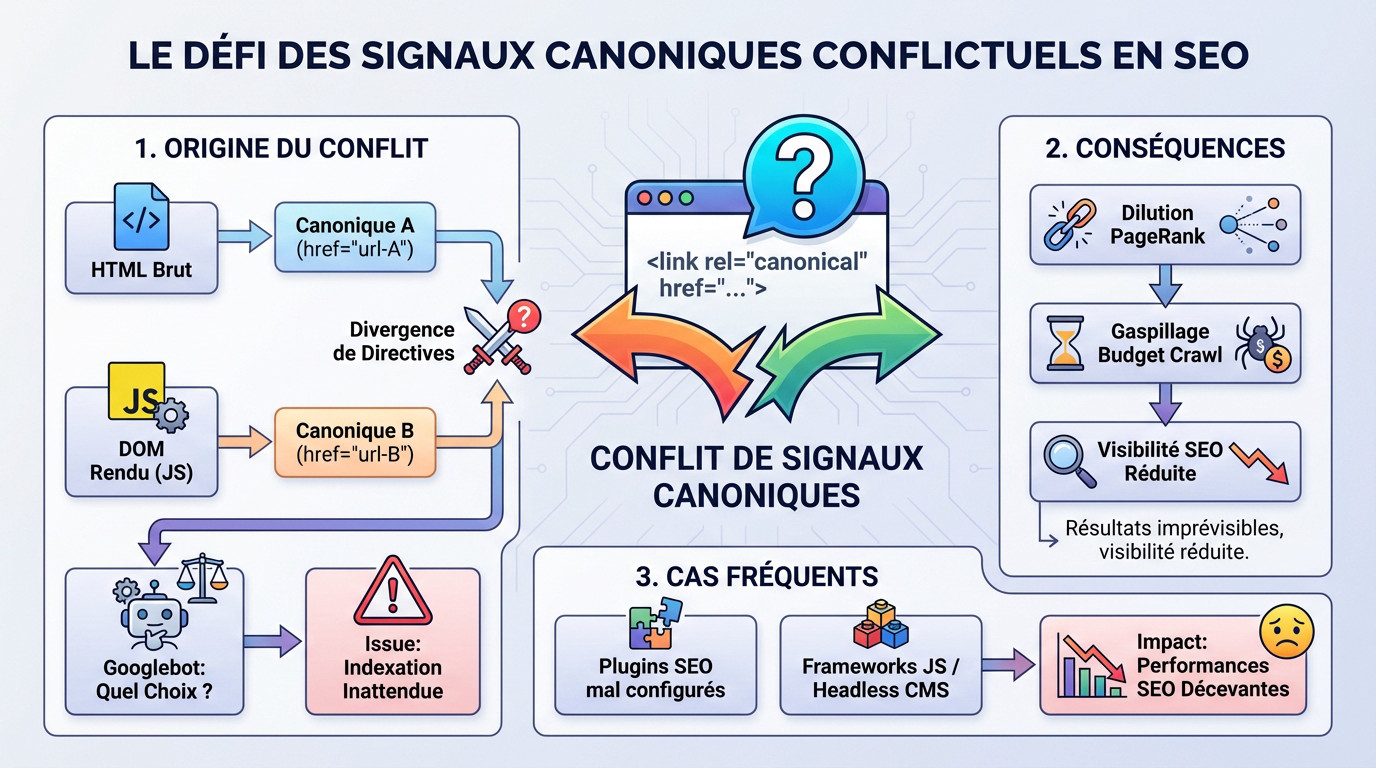
HTML brut vs. DOM rendu : le champ de bataille
Le conflit naît lorsqu’une URL canonique est déclarée dans le <head> du HTML initial. Puis, le JavaScript s’exécute et la modifie ou en ajoute une autre.
Google se retrouve avec deux directives différentes pour la même page. L’une issue du crawl, l’autre du rendu.
Le moteur de recherche doit alors choisir quel signal suivre. Ce choix peut mener à une indexation inattendue, où la mauvaise version de la page est choisie comme canonique, voire aucune.
Les conséquences d’une canonicalisation ambiguë
Le principal risque est la dilution du PageRank et des signaux de pertinence. Les signaux sont répartis entre plusieurs URL au lieu d’être consolidés sur une seule.
Des signaux canoniques contradictoires entre le HTML brut et la sortie JavaScript peuvent entraîner des résultats d’indexation totalement imprévisibles et nuire à votre visibilité.
Cela peut aussi entraîner un gaspillage du budget de crawl. Googlebot passe du temps à explorer et rendre des pages qui ne devraient pas être indexées.
Un problème plus fréquent qu’on ne le pense
Ce problème n’est pas réservé aux configurations exotiques. Une incohérence google javascript seo url survient souvent lorsqu’un plugin génère une canonique dans le HTML, tandis que le framework en gère une autre.
Les modules de gestion de contenu (headless CMS) peuvent aussi être une source de conflit s’ils ne sont pas synchronisés.
Beaucoup de sites vivent avec ce problème sans le savoir. Ils constatent juste des performances SEO décevantes ou une indexation erratique de leurs pages.
Les stratégies validées par Google pour une canonicalisation propre
Face aux risques de conflits d’indexation, Google préconise des solutions techniques précises et directes pour harmoniser les signaux.
La méthode prioritaire : la cohérence absolue
La pratique recommandée par le moteur de recherche vise la simplicité. L’URL canonique doit être définie une seule fois, directement dans la réponse HTML initiale renvoyée par le serveur.
Cette adresse doit correspondre exactement à l’URL finale présente sur la page après le rendu complet du JavaScript. Aucune divergence ne doit exister entre ces deux états.
Le script ne doit jamais modifier, supprimer ou ajouter de balise canonique par la suite. Il laisse l’élément HTML intact. La cohérence des signaux demeure ainsi totale.
L’alternative : la stratégie du « vide » initial
Certaines architectures techniques imposent que le JavaScript définisse l’URL canonique. Cette situation survient lorsque l’adresse dépend d’une logique complexe ou d’une action utilisateur connue uniquement côté client.
Dans ce scénario spécifique, la directive est de ne pas inclure de balise canonique au sein du HTML brut.
Cette méthode supprime tout risque de conflit. Google ne détecte aucun signal au départ, puis identifie une balise unique et claire une fois le rendu terminé.
Les deux approches recommandées
Ces deux stratégies structurent efficacement la relation google javascript seo url. Le choix de la méthode dépend exclusivement de votre architecture technique.
- Scénario 1 (Préféré) : Définir la balise
rel="canonical"dans la réponse HTML du serveur et veiller à ce que le JavaScript ne la modifie pas. L’URL reste identique avant et après le rendu. - Scénario 2 (Alternative) : Si le JavaScript doit impérativement définir la balise canonique, il faut s’abstenir d’en inclure une dans le code HTML initial pour éviter tout signal contradictoire.
L’injection de balise canonique par JavaScript : une fausse bonne idée ?
C’est une zone grise technique qui mérite qu’on s’y arrête. L’injection via JS fonctionne, certes, mais elle ouvre la porte à des complications inutiles.
Une technique supportée mais non recommandée
Google confirme que son service de rendu web (WRS) est capable de voir et d’interpréter une balise canonique injectée via JavaScript. Techniquement, c’est donc supporté par l’infrastructure actuelle. Le moteur digère l’information sans blocage immédiat lors de son passage.
Pourtant, la documentation le déconseille activement. La raison est simple : le risque d’erreurs d’implémentation est trop élevé. Pourquoi jouer avec le feu quand la stabilité de l’indexation est en jeu ?
C’est une méthode fragile qui peut facilement se briser lors d’une mise à jour du code ou d’un plugin.
Les erreurs d’implémentation courantes
Les erreurs d’injection sont la cause principale des problèmes de canonicalisation en JS. C’est un fait technique indéniable.
- Duplication de balises : Le script JS ajoute une nouvelle balise
rel="canonical"sans vérifier s’il en existe déjà une. La page se retrouve avec plusieurs balises, ce qui invalide le signal. - Modification incorrecte : Le script tente de modifier l’attribut
hrefd’une balise existante mais échoue, laissant une balise vide ou erronée. - Timing d’injection : La balise est injectée trop tard dans le cycle de vie de la page, et le robot de Google ne la prend pas en compte.
La règle d’or : une seule balise canonique finale
Quelle que soit la méthode choisie, la règle finale est immuable. Après le rendu complet de la page par JavaScript, il ne doit y avoir qu’une et une seule balise rel="canonical" dans le DOM. C’est vital pour la gestion du google javascript seo url.
La présence d’une unique balise canonique sur une page après le rendu complet est la règle non négociable pour garantir une interprétation correcte par Google.
Auditer et diagnostiquer les problèmes de canonicalisation JS
L’outil d’inspection d’URL, votre meilleur allié
L’outil le plus direct pour analyser la problématique google javascript seo url est l’Outil d’inspection d’URL dans la Search Console. Il est conçu pour ça.
Il permet de comparer le HTML brut (ce que Googlebot voit au premier crawl) et la capture d’écran du DOM rendu (ce que Google voit après exécution du JS).
C’est ici que l’on peut visualiser directement la présence, l’absence ou la duplication des balises canoniques entre les deux versions.
Le processus de vérification étape par étape
Pour un audit efficace, la méthode doit être rigoureuse.
- Inspecter l’URL : Saisir l’URL concernée dans l’outil d’inspection de la Search Console.
- Comparer les codes : Utiliser la fonction « Afficher la page explorée » pour voir le HTML brut. Ensuite, lancer le « Test en direct » et consulter le HTML rendu.
- Rechercher « canonical » : Dans les deux versions du code, rechercher la chaîne de caractères
rel="canonical". - Analyser les incohérences : Vérifier si la balise est absente, présente dans les deux, ou différente entre le brut et le rendu.
Coordination client-serveur et SEO technique
La solution réside dans une parfaite coordination entre les équipes de développement front-end et back-end (ou DevOps). Le SEO n’est plus l’affaire d’une seule personne.
Les développeurs doivent comprendre les implications de leur code JS sur le référencement. Les SEO doivent comprendre les contraintes techniques du rendu.
Cet enjeu est au cœur du SEO technique moderne, où la technique et le contenu sont indissociables.
Gérer la structure des url au-delà de la balise canonique
La balise canonique n’est qu’une partie du puzzle. Cette dernière section élargit le sujet à la gestion globale des URL dans un environnement JavaScript.
Fragments d’URL (#) : une pratique à abandonner
Une erreur historique du SEO JavaScript consistait à utiliser les fragments d’URL, le fameux « hash », pour simuler la navigation. C’est une technique obsolète qui bloque littéralement la lecture par les robots. Vous sabotez votre propre référencement en persistant dans cette voie.
Le problème est technique : Google ignore généralement tout ce qui se trouve après un `#` lors de l’indexation. Le contenu situé derrière cette barrière n’existe simplement pas pour le moteur.
Utiliser une adresse comme mondomaine.com/#/page-contact au lieu de mondomaine.com/page-contact/ revient à rendre la page invisible. Google ne voit que la racine du site. Cette pratique est nuisible et doit disparaître de vos développements.
L’API History pour des URL propres en SPA
La solution moderne pour la navigation dans les Single Page Applications (SPA) est l’API History de JavaScript. Elle est désormais supportée par l’ensemble des navigateurs modernes. C’est le standard technique à adopter immédiatement.
Elle permet de manipuler l’URL affichée dans la barre d’adresse du navigateur sans recharger la page. L’expérience utilisateur reste fluide. C’est totalement transparent pour le visiteur.
Surtout, elle génère des URL réelles et explorables que Google peut traiter comme des pages distinctes.
Consolider les URL dynamiques (filtres, tris)
Un défi majeur reste la gestion des URL avec des paramètres de tri ou de filtre, souvent générées côté client. C’est un point critique pour optimiser votre stratégie google javascript seo url. Ces variations infinies créent du bruit inutile.
Si chaque combinaison génère une URL indexable, cela crée une quantité massive de contenu quasi-dupliqué. Vous diluez la pertinence de vos pages. C’est un piège mortel pour votre budget de crawl.
Ici, la balise canonique est une solution technique indispensable. Il faut définir une URL de base comme canonique pour toutes les variations de filtres. Cela nettoie l’indexation de votre site.
La gestion des URL canoniques dans un environnement JavaScript exige une rigueur technique absolue. Google traite le code en deux temps, imposant une cohérence parfaite entre le HTML brut et le DOM rendu. L’alignement entre les équipes de développement et les experts SEO devient indispensable pour garantir une indexation optimale et préserver le budget de crawl.
FAQ
Comment Google traite-t-il les URL canoniques sur les pages générées en JavaScript ?
Google analyse les pages web selon un processus en deux étapes : l’exploration du HTML brut, suivie de l’exécution du JavaScript pour obtenir le DOM rendu. La canonicalisation est évaluée lors de ces deux phases distinctes. Le moteur cherche une directive dans la réponse initiale du serveur, puis vérifie de nouveau après le rendu complet.
Il est crucial que les signaux envoyés soient cohérents entre ces deux étapes. Une divergence entre le HTML initial et le rendu final peut entraîner des erreurs d’interprétation. Google recommande une uniformité stricte pour garantir une indexation optimale.
Quels sont les risques de signaux canoniques contradictoires ?
Un conflit survient lorsque le HTML brut déclare une URL canonique différente de celle générée par le JavaScript. Cette situation envoie des signaux ambigus aux algorithmes de Google. Le moteur de recherche doit alors arbitrer, ce qui peut mener à des résultats imprévisibles.
Les conséquences incluent souvent une indexation de la mauvaise version de l’URL ou une dilution du PageRank. Pour éviter cela, la balise rel="canonical" finale doit être unique et identique à celle présente (ou absente) lors du crawl initial.
Est-il recommandé d’injecter la balise canonique via JavaScript ?
Bien que le WRS (Web Rendering Service) de Google supporte l’injection de balises canoniques via JavaScript, cette méthode est déconseillée. Elle augmente le risque d’erreurs d’implémentation, comme la duplication de balises ou des problèmes de timing d’exécution.
La meilleure pratique consiste à définir l’URL canonique directement dans le code HTML fourni par le serveur. Si l’injection JavaScript est inévitable, il est impératif de ne placer aucune balise canonique dans le HTML brut pour éviter les conflits.
Comment vérifier la validité des canoniques JS avec la Search Console ?
L’Outil d’inspection d’URL de la Google Search Console est l’instrument de diagnostic principal. Il permet de comparer le code source de la « page explorée » (HTML brut) avec le résultat du « test en direct » (DOM rendu). Cette double vérification est indispensable.
L’analyse doit confirmer la présence d’une unique balise rel="canonical" dans le rendu final. Elle permet aussi de s’assurer que le JavaScript n’a pas modifié l’URL de manière inattendue par rapport à la réponse serveur.
Pourquoi l’API History est-elle supérieure aux fragments d’URL (#) pour le SEO ?
Les fragments d’URL, identifiés par le symbole # (hash), ne sont généralement pas traités comme des pages distinctes par Google. Le contenu situé après ce symbole est souvent ignoré lors de l’indexation. Cela rend des sections entières d’une application invisibles pour le moteur.
L’utilisation de l’API History permet de manipuler l’URL du navigateur pour créer des adresses propres et distinctes. Cette technique assure que chaque vue d’une Single Page Application (SPA) possède une URL réelle, explorable et indexable.



