
L’essentiel à retenir : Google Research révolutionne l’IA avec TurboQuant, un algorithme capable de diviser par six l’empreinte mémoire des caches KV sans aucun réentraînement. Cette prouesse mathématique permet de gérer des contextes massifs sur vos infrastructures actuelles tout en boostant la vitesse de calcul par 8 sur GPU Nvidia H100. Pour en discuter directement: Contactez- nous!
Saturez-vous régulièrement la mémoire de vos GPU lors de l’exécution de modèles d’IA aux contextes étendus ? Google Research vient de dévoiler google turboquant, un algorithme révolutionnaire capable de compresser les caches KV à seulement 3 bits. Vous allez découvrir comment cette innovation multiplie par huit les performances sur Nvidia H100 tout en divisant les besoins en RAM par six, le tout sans aucun réentraînement nécessaire.
Algorithme Google TurboQuant et gestion des caches KV
Après des mois de spéculation sur l’efficacité des LLM, Google Research vient de frapper un grand coup avec TurboQuant, une solution qui s’attaque au cœur du problème : la mémoire vive des GPU.
Rôle du Key-Value Cache dans l’inférence
Le KV Cache agit comme le journal de bord des tokens déjà générés. Il stocke les calculs passés pour éviter de recalculer tout le contexte. Chaque nouveau mot produit s’appuie ainsi sur ces données.
Mais attention, ce cache grandit de manière linéaire. Plus votre texte est long, plus la RAM du GPU sature. C’est le point de rupture pour les modèles gérant 128k tokens ou plus.
Pour contrer cette saturation, Google Research a développé TurboQuant. Cet outil permet une compression massive sans sacrifier la précision de vos modèles favoris.
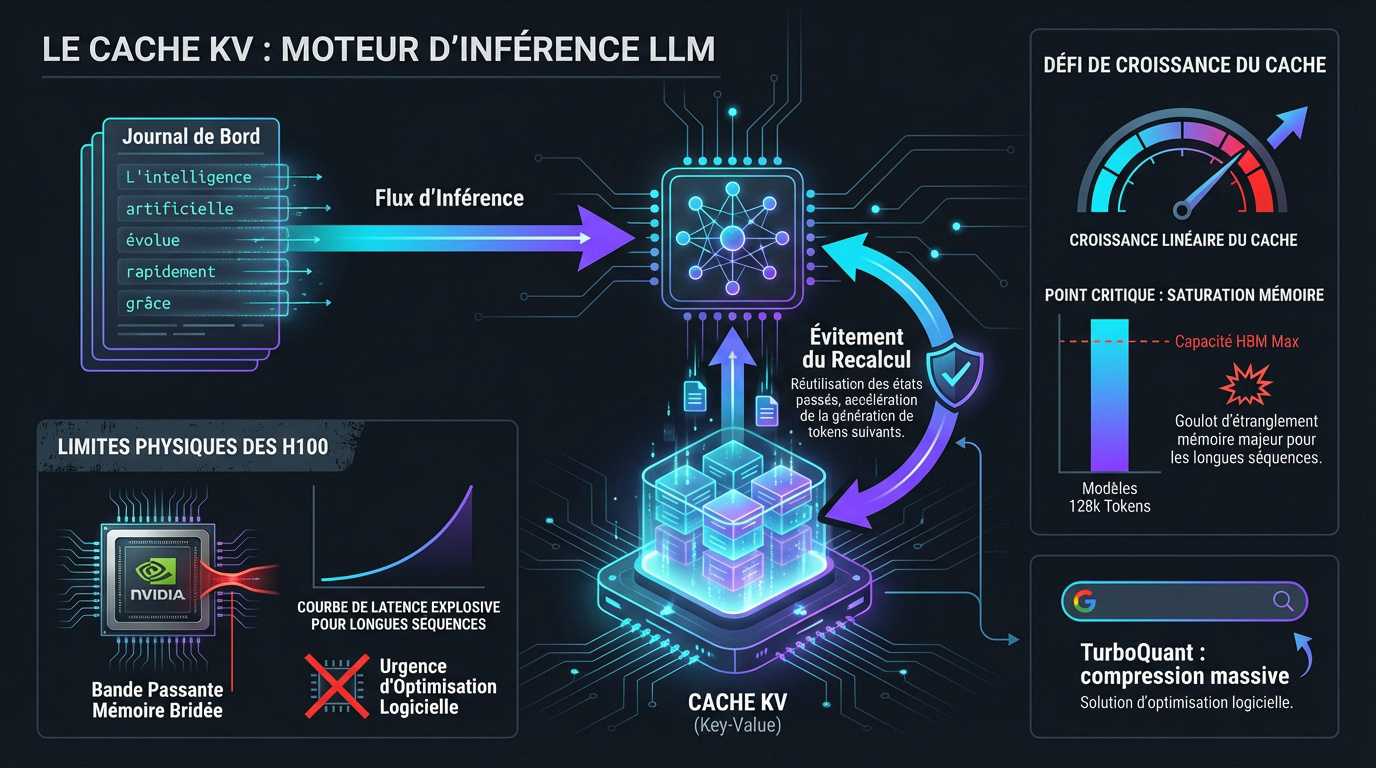
Limites physiques des accélérateurs Nvidia H100
Sur l’architecture Hopper, le goulot d’étranglement est réel. La puissance brute est impressionnante, mais la bande passante mémoire bride tout. En production intensive, le système finit par stagner.
Vous avez déjà remarqué cette chute de latence ? Sur les séquences longues, le temps par token explose. Le GPU jongle péniblement avec des gigaoctets de données KV non compressées.
C’est problématique pour les Google AI Overviews. Ces fonctionnalités exigent une réactivité immédiate pour satisfaire les utilisateurs pressés.
Bref, l’optimisation logicielle devient urgente. Les limites matérielles actuelles de Nvidia imposent de coder plus intelligemment.
Fondements mathématiques de PolarQuant et QJL
Pour briser ce plafond de verre, Google n’a pas simplement ajouté des serveurs, mais a repensé la géométrie même des données stockées.
Conversion géométrique en coordonnées polaires
Imaginez délaisser les grilles carrées classiques. PolarQuant convertit les vecteurs cartésiens (X, Y) en rayons et angles. Cette méthode isole la magnitude de la direction. C’est une approche mathématique très élégante pour simplifier l’information.
L’avantage pour la compression est flagrant. En traitant séparément la norme et l’orientation, on réduit l’espace nécessaire. On garde l’essence sémantique sans s’encombrer de données inutiles. C’est brillant.
TurboQuant opère en deux étapes clés : une compression utilisant PolarQuant et l’élimination des erreurs via l’algorithme QJL.
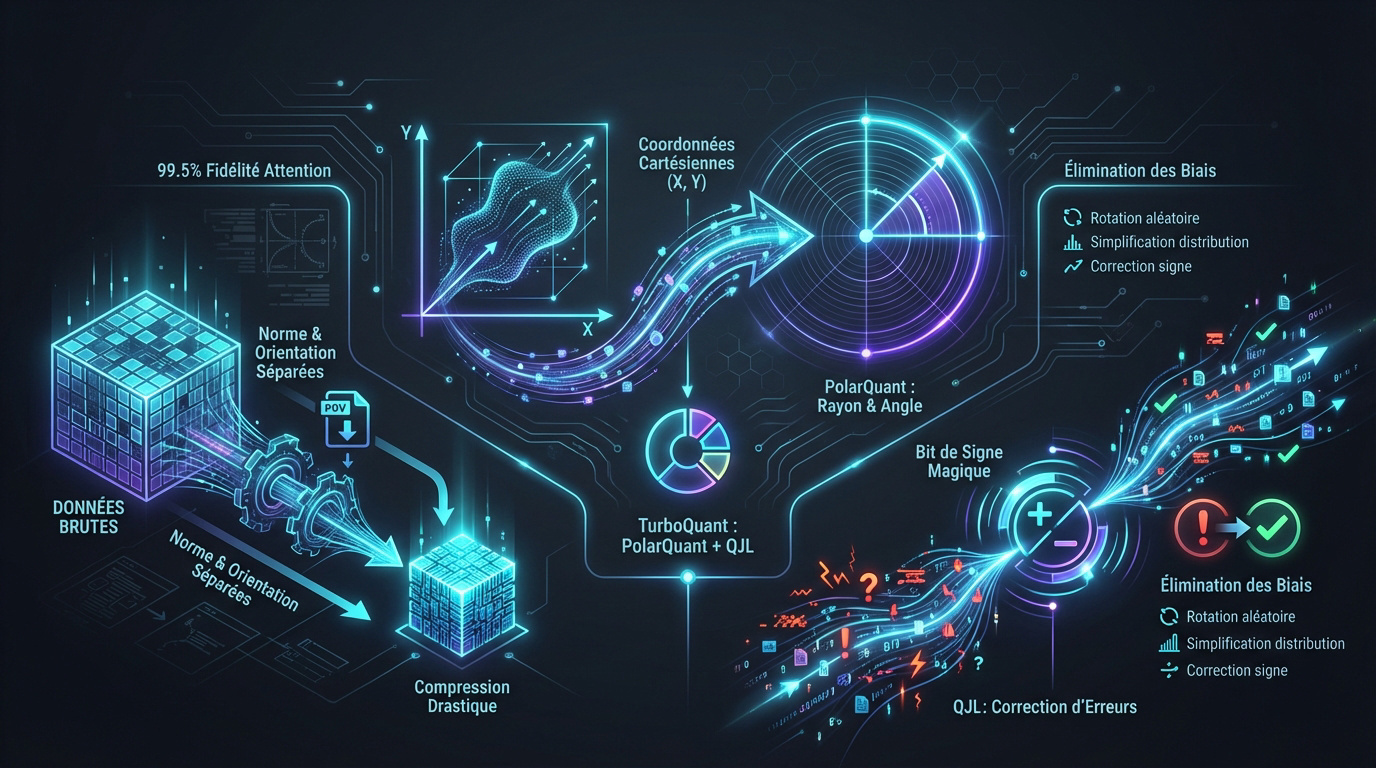
Correction d’erreurs par le bit de signe QJL
Voici le secret : la transformée Quantized Johnson-Lindenstrauss (QJL). Ce mécanisme gère les erreurs résiduelles de manière probabiliste. C’est là que réside le génie de la stabilité du modèle. Vous suivez ?
L’élimination des biais devient alors un jeu d’enfant. Un simple bit de signe suffit à corriger les déviances systématiques. Même avec une quantification à 3 bits, la précision reste incroyable.
- Rotation aléatoire des données
- Simplification de la distribution
- Correction par bit de signe
Cette précision mathématique permet de conserver 99,5% de la fidélité de l’attention. C’est presque invisible.
Quels sont les gains réels sur Nvidia H100 ?
La théorie est séduisante, mais voyons comment ce monstre mathématique se comporte une fois injecté dans les GPU les plus puissants du marché.
Analyse des benchmarks LongBench et RULER
TurboQuant réduit la mémoire du cache KV par six. Il booste aussi les performances par huit sur les puces H100.
Sur le test « Needle In A Haystack », la précision reste bluffante malgré une compression à 3 bits. L’algorithme retrouve l’information sans erreur. Les benchmarks LongBench confirment d’ailleurs cette nette supériorité technique face aux solutions actuelles.
Ces avancées s’inscrivent parfaitement dans la nouvelle stratégie IA de Google en 2025 pour optimiser les infrastructures.
La compression extrême n’est plus l’ennemie de la performance. La mémoire de travail reste intacte.
Accélération des logits et compression à 3 bits
Le gain de vitesse est spectaculaire pour les développeurs. Le calcul des logits d’attention devient huit fois plus rapide. On oublie enfin la lourdeur des clés 32 bits classiques.
Les méthodes de quantification standards, comme le 4-bit INT, sont totalement distancées. TurboQuant offre un rapport fidélité et poids imbattable. Il redéfinit clairement la norme du secteur.
Cette technologie permet une l’accélération de la mémoire IA par 8 sur le matériel récent.
Traiter des contextes massifs sur un seul nœud devient possible. L’efficacité est désormais une réalité concrète.
Impact économique de l’optimisation sans réentraînement
Au-delà des prouesses techniques, c’est l’aspect financier qui risque de faire basculer l’industrie vers cette nouvelle norme.
Adoption facilitée par la nature data-oblivious
Oubliez les factures de calcul astronomiques. TurboQuant est « data-oblivious », ce qui signifie qu’il s’applique instantanément. Vous n’avez pas besoin de dépenser un centime en réentraînement coûteux.
L’intégration est un jeu d’enfant. Vos ingénieurs l’injectent dans des systèmes distribués sans toucher à l’architecture. C’est un gain de temps massif pour vos déploiements immédiats.
Voici pourquoi cette approche change la donne :
- Pas de phase de calibration
- Compatibilité immédiate LLM
- Usage gratuit pour les entreprises
Réduction des coûts d’infrastructure GPU
Diviser le besoin en RAM par six est une prouesse. Cela permet de faire tourner des modèles géants sur des infrastructures modestes. C’est une victoire éclatante pour la sobriété numérique actuelle.
Le potentiel pour l’IA embarquée est immense. Vos smartphones géreront bientôt des contextes longs sans aucune surchauffe matérielle.
Pour en discuter directement: Contactez- nous!
En fin de compte, TurboQuant rend l’IA de pointe accessible. Elle devient enfin économiquement viable.
Grâce à TurboQuant, Google Research propulse l’efficacité des LLM vers de nouveaux sommets en compressant les caches KV à 3 bits sans sacrifier la précision. Cette prouesse technique décuple par huit les performances sur Nvidia H100, offrant une gestion fluide des contextes massifs sans réentraînement coûteux. Adoptez dès maintenant cette optimisation pour transformer radicalement votre infrastructure IA !
FAQ
Qu’est-ce que l’algorithme TurboQuant développé par Google ?
TurboQuant est une petite révolution signée Google Research ! Il s’agit d’un algorithme de compression ultra-intelligent conçu pour booster l’efficacité des grands modèles de langage (LLM). Son secret ? Il réduit drastiquement la mémoire occupée par ce qu’on appelle le « KV cache » (le journal de bord des conversations de l’IA) sans que l’intelligence artificielle ne perde le fil ou ne devienne moins précise.
Imaginez que vous puissiez diviser par six la place nécessaire pour stocker les souvenirs immédiats d’une IA, tout en accélérant ses réponses. C’est exactement ce que fait TurboQuant, le tout sans avoir besoin de réentraîner le modèle, ce qui permet une adoption immédiate et gratuite pour les entreprises.
Comment TurboQuant parvient-il à compresser les données à seulement 3 bits ?
C’est là que la magie mathématique opère ! TurboQuant utilise une approche en deux étapes. D’abord, PolarQuant transforme les données complexes en coordonnées polaires (rayons et angles), ce qui simplifie leur stockage. Ensuite, l’algorithme QJL intervient comme un correcteur d’erreurs ultra-rapide en utilisant un simple « bit de signe » pour stabiliser le tout.
Cette combinaison permet de descendre à un niveau de compression extrême de 3 bits. Pour vous donner une idée, c’est comme si vous arriviez à résumer un livre entier en quelques pages sans oublier un seul détail important de l’intrigue. Le résultat est bluffant : 99,5 % de fidélité conservée !
Quels sont les gains de performance réels sur les processeurs Nvidia H100 ?
Tenez-vous bien, car les chiffres sont impressionnants ! Sur les puissants GPU Nvidia H100, TurboQuant permet de multiplier la vitesse de calcul par 8. En compressant les données, il libère de la bande passante mémoire, ce qui permet à l’IA de générer du texte beaucoup plus rapidement, même avec des contextes très longs.
En plus de cette vitesse fulgurante, le besoin en mémoire vive est réduit d’au moins six fois. Cela signifie que vous pouvez faire tourner des modèles d’IA massifs sur des infrastructures plus petites et moins coûteuses, rendant l’IA de pointe enfin accessible et économiquement viable.
Est-ce que l’utilisation de TurboQuant dégrade la qualité des réponses de l’IA ?
C’est la question que tout le monde se pose, et la réponse est un « non » catégorique ! Les tests effectués sur des benchmarks de référence comme LongBench ou RULER montrent que TurboQuant égale, et surpasse parfois, les méthodes classiques. Même avec une compression à 3 bits, l’IA reste capable de retrouver une information précise dans une montagne de données.
Grâce à son mécanisme de correction d’erreurs mathématiques, l’algorithme élimine les biais systématiques. Vous profitez donc d’une IA beaucoup plus légère et rapide, mais tout aussi intelligente et fiable qu’une version non compressée. C’est le meilleur des deux mondes !
TurboQuant est-il difficile à installer sur des systèmes existants ?
Pas du tout, et c’est l’un de ses plus grands atouts ! TurboQuant est ce qu’on appelle « data-oblivious ». Cela signifie qu’il s’adapte directement à vos modèles actuels (comme Gemma ou Mistral) sans nécessiter de phase de calibration longue ou coûteuse. Les ingénieurs peuvent l’intégrer en un clin d’œil dans leurs systèmes.
Comme il ne demande aucun réentraînement, il n’y a pas de frais cachés. Des implémentations sont déjà disponibles via des packages Python comme turboquant ou pour llama.cpp, facilitant son déploiement aussi bien sur des serveurs professionnels que sur des appareils locaux comme vos futurs smartphones boostés à l’IA.



