

L’essentiel à retenir : l’intégration des LLM et des bases vectorielles automatise efficacement les redirections 301 massives sur WordPress. Cette solution sémantique optimise le budget de crawl et sécurise l’autorité SEO en liant les pages obsolètes aux contenus les plus pertinents. L’usage de Google Vertex AI garantit une précision supérieure pour traiter des millions d’URL.
Face à l’accumulation critique des erreurs 404, la maintenance manuelle des redirections sature les ressources techniques des sites à fort volume. L’intégration des technologies llm bases de données vectorielles wordpress seo automatise désormais le traitement des URLs obsolètes par une analyse sémantique précise. Cette approche technique transforme la gestion des liens morts en levier pour optimiser le budget de crawl et renforcer l’autorité thématique du domaine.
Le défi des redirections massives sur WordPress
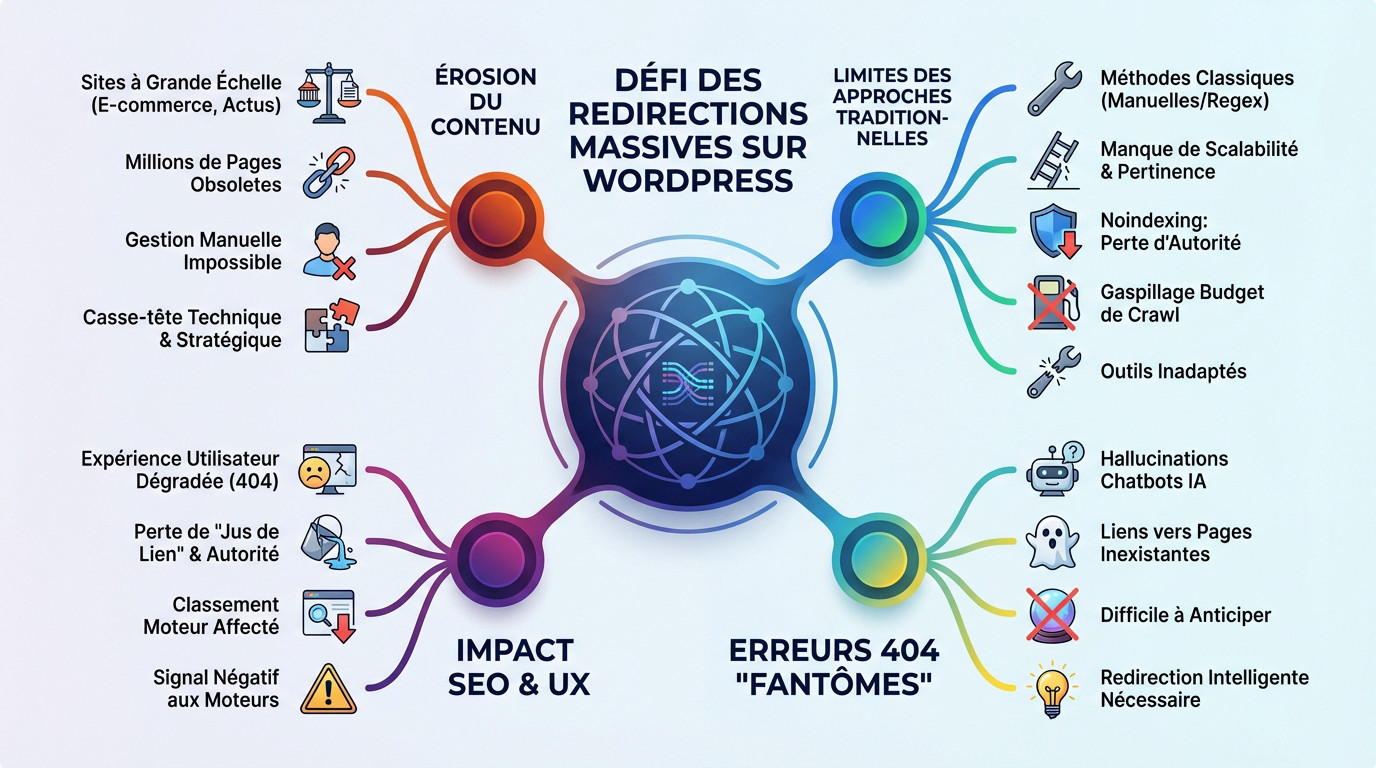
L’érosion du contenu : un problème à grande échelle
La gestion des redirections 301 est une tâche complexe pour les sites à très grande échelle. Pensez aux sites e-commerce avec des fiches produits obsolètes ou aux publications d’actualités avec des articles périmés.
Ajoutez les annuaires ou les sites d’offres d’emploi. Le volume est colossal : des milliers, voire des millions de pages. La gestion manuelle devient alors impossible et constitue une source majeure d’erreurs.
Cette érosion de contenu est un véritable casse-tête technique et stratégique.
Les limites des approches traditionnelles
Les méthodes classiques, redirections manuelles ou règles regex, montrent vite leurs limites. Elles manquent de scalabilité et de la pertinence sémantique offerte par le combo llm bases de données vectorielles wordpress seo.
Le « noindexing » n’est pas une solution suffisante. Il ne transfère pas l’autorité acquise par l’ancienne page et laisse les liens externes pointer vers une ressource inutile, gaspillant ainsi le budget de crawl.
Le constat est simple : les outils traditionnels ne sont pas adaptés à la complexité des sites modernes.
L’impact sur le SEO et l’expérience utilisateur
Une mauvaise gestion entraîne des conséquences négatives. Pour l’utilisateur, c’est une expérience dégradée due à la frustration des erreurs 404. Pour le SEO, c’est une perte de « jus de lien » et une dilution de l’autorité.
Cela peut affecter négativement le classement dans les moteurs de recherche et la perception de la marque.
Une mauvaise gestion des URL mortes envoie un signal négatif aux moteurs de recherche sur la maintenance du site.
L’émergence des erreurs 404 « fantômes »
Un nouveau problème surgit : les hallucinations des chatbots IA. Ces intelligences artificielles génèrent parfois des liens vers des pages qui n’ont jamais existé, créant ainsi une nouvelle vague massive et imprévisible d’erreurs 404.
Ces erreurs sont difficiles à anticiper. Elles apparaissent directement dans les logs serveurs ou la Google Search Console.
Cela renforce le besoin d’un système capable de rediriger intelligemment. Éviter les erreurs des LLM est devenu un enjeu pour la qualité de l’expérience web.
Les nouvelles briques technologiques : LLM et bases vectorielles
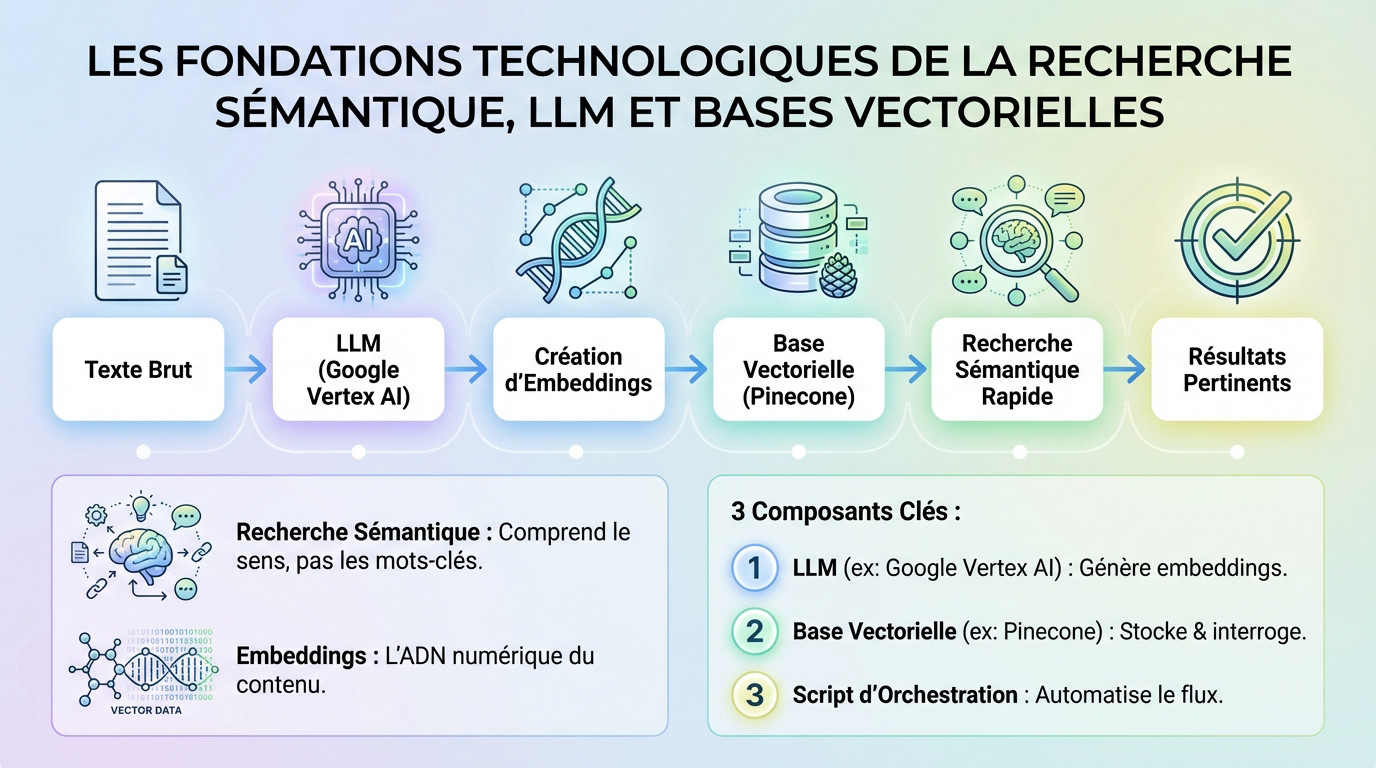
Face au volume massif d’URLs obsolètes, l’approche manuelle atteint ses limites. La réponse technique efficace réside dans l’alliance de deux technologies : les LLM et les bases de données vectorielles.
Au-delà des mots-clés : la recherche sémantique
La recherche lexicale traditionnelle montre rapidement ses limites techniques. Elle se focalise uniquement sur la correspondance exacte des termes, ignorant totalement le contexte ou l’intention réelle cachée derrière une requête utilisateur.
La recherche sémantique change radicalement cette approche. Son objectif n’est pas de repérer des mots identiques, mais d’identifier des concepts similaires. Cette technologie permet enfin de rapprocher deux contenus qui traitent du même sujet, même s’ils utilisent un vocabulaire différent.
C’est précisément ce changement de paradigme technique qui rend l’automatisation des redirections possible.
Les embeddings, l’adn numérique du contenu
Un embedding, ou vecteur de texte, constitue une représentation numérique précise d’un segment de contenu. Il peut s’agir d’un simple mot, d’une phrase complète ou même d’un article entier.
Cette traduction mathématique capture le sens sémantique profond. Dans un espace vectoriel, des textes aux significations proches possèdent des coordonnées voisines. C’est la mission des grands modèles de langage (LLM) de générer ces empreintes numériques uniques.
En somme, les embeddings convertissent le langage humain complexe en un format logique.
Pinecone : une bibliothèque pour le sens
Le rôle d’une base de données vectorielle est central dans cette architecture. Sa fonction première consiste à stocker, organiser et indexer efficacement des millions, voire des milliards de vecteurs générés.
Pinecone s’impose comme la référence technique pour ce processus critique. L’outil permet d’exécuter des recherches de similarité à une vitesse fulgurante. On lui soumet un vecteur source, et il renvoie instantanément les vecteurs les plus proches mathématiquement.
Il agit comme le moteur de recherche sémantique qui identifie les meilleurs candidats pour la redirection.
Le rôle des llm dans la création des vecteurs
Il faut dissiper un malentendu : les LLM ne servent pas ici à rédiger du texte. Leur fonction unique est de transformer le contenu textuel brut en vecteurs numériques (embeddings) exploitables.
Des modèles spécialisés, tels que `text-embedding-005` de Google Vertex AI, sont spécifiquement entraînés pour cette tâche. Ils excellent à capturer la moindre nuance sémantique des textes pour une précision maximale.
Voici les trois composants clés du système :
- Un LLM (ex: Google Vertex AI) pour générer les embeddings.
- Une base de données vectorielle (ex: Pinecone) pour stocker et interroger les embeddings.
- Un script d’orchestration pour automatiser le flux de travail.
Le processus d’automatisation des redirections 301
Maintenant que les briques technologiques sont posées, voyons comment elles s’assemblent pour créer un flux de travail cohérent et automatisé. Cette section décrit le processus de bout en bout, de l’identification des problèmes à la solution.
Étape 1 : identifier les url à traiter
La liste des URL à rediriger provient de données concrètes et vérifiables. Les sources principales restent les rapports d’erreurs 404 issus de Google Analytics 4 et de la Google Search Console. Les logs serveurs constituent également une ressource précieuse pour repérer les liens brisés.
Cette liste peut aussi contenir des articles existants mais obsolètes que l’on souhaite « élaguer » (pruning) pour consolider le contenu. Cela permet de nettoyer la structure du site.
L’objectif est de constituer un fichier source propre, souvent structuré au format CSV.
Étape 2 : vectoriser les contenus source et cible
La première phase consiste à transformer l’ensemble des articles valides du site en vecteurs. Ces pages représentent les cibles potentielles pour les futures redirections et assurent la pertinence sémantique.
Ces vecteurs, ou embeddings, sont ensuite stockés et indexés dans la base de données vectorielle Pinecone. Cette base constitue la bibliothèque de connaissance du site pour le couplage llm bases de données vectorielles wordpress seo. Le texte utilisé est le titre de l’article.
Ensuite, le script prend chaque URL de la liste à traiter et génère son propre vecteur.
Étape 3 : interroger la base pour trouver la meilleure correspondance
C’est le cœur du processus. Le vecteur de l’URL source est utilisé pour lancer une requête de similarité dans Pinecone. La base renvoie une liste d’articles existants, classés par pertinence sémantique.
Des filtres peuvent être appliqués pour affiner la recherche. Par exemple, en ne cherchant que des articles plus récents grâce à un filtre sur l’année de publication.
Le script sélectionne le premier résultat comme le meilleur candidat pour la redirection, après avoir écarté les correspondances invalides.
Étape 4 : générer la carte de redirection finale
Le résultat final du script est un fichier, typiquement un fichier CSV. Ce fichier agit comme une « carte de redirection » prête à l’emploi pour les équipes techniques.
Chaque ligne du fichier contient une paire : l’URL source (obsolète) et l’URL de destination (le meilleur candidat trouvé). Un score de similarité est souvent inclus pour validation.
Ce processus transforme une tâche manuelle fastidieuse et subjective en une opération automatisée, scalable et basée sur une compréhension sémantique réelle du contenu.
Préparation des données : la clé d’une redirection pertinente
Structurer les données d’entrée via csv
Le format CSV est privilégié pour sa simplicité et sa compatibilité universelle. Il structure efficacement les données pour les LLM et bases de données vectorielles en SEO WordPress. Ce fichier doit impérativement lister les URL à rediriger. Le titre de la page, s’il est connu, constitue la donnée prioritaire.
Ce document agit comme une feuille de route précise pour le script d’automatisation. Il définit le périmètre d’action exact du modèle lors du traitement.
Une structuration rigoureuse des données initiales constitue la première étape vers un résultat technique de haute qualité.
Gérer les pages 404 sans titre : l’astuce du slug
Un défi technique fréquent survient lors du traitement d’une URL 404 dont le titre original est introuvable. Le script nécessite pourtant une base textuelle pour générer un embedding cohérent.
La solution réside dans l’exploitation du slug de l’URL. Le script extrait les termes significatifs, nettoie les séparateurs comme les tirets, et utilise cette chaîne de caractères épurée comme source principale pour la vectorisation.
Cette méthode permet d’identifier une correspondance sémantique pertinente, même en l’absence totale du titre complet.
Affiner la recherche avec des métadonnées
Pour accroître la précision, l’ajout de colonnes optionnelles au fichier CSV est recommandé. L’intégration d’une colonne `primary_category` s’avère particulièrement efficace pour le filtrage des résultats.
Cette métadonnée contraint la recherche vectorielle à une catégorie spécifique du site. Elle empêche ainsi la redirection d’un article technique vers un contenu marketing, même si leurs titres présentent une forte similarité.
L’utilisation du filtre par année de publication, ou `PUBLISH_YEAR_FILTER`, privilégie quant à lui les contenus les plus récents.
Prévenir les boucles de redirection
Un risque majeur de l’automatisation réside dans la création de boucles de redirection (A vers B, puis B vers A). Ce phénomène représente un véritable poison pour le SEO.
Le script intègre des garde-fous stricts. Il vérifie que l’URL de destination diffère de l’URL source. Il s’assure également qu’elle ne figure pas dans la liste des autres URL destinées à la suppression.
Ces mécanismes de sécurité sont requis pour garantir un déploiement fiable sans erreur.
Le choix du modèle d’embedding : un arbitrage entre coût et précision
Le moteur de ce système est le modèle de langage qui génère les embeddings. Tous les modèles ne se valent pas. Cette section compare les options disponibles et analyse le compromis entre la performance et le coût.
Google vertex ai : la référence pour la pertinence
Le modèle `text-embedding-005` de Google Vertex AI s’impose comme une référence pour allier llm bases de données vectorielles wordpress seo. Il est spécifiquement optimisé pour les tâches de recherche et de similarité (`RETRIEVAL_QUERY`). Cette configuration affine la compréhension des intentions. C’est une solution de haute qualité.
Ce type de tâche est jugé plus efficace que `RETRIEVAL_DOCUMENT` pour ce cas d’usage précis. La qualité de l’embedding est supérieure. Les vecteurs générés offrent une meilleure finesse.
L’expérience de Search Engine Journal montre sa supériorité pour trouver des correspondances pertinentes. C’est factuel.
Le cas concret de l’url ‘/what-is-eat/’
Pour illustrer la précision de Vertex AI, l’exemple de l’URL `/what-is-eat/` est parlant. Le système a trouvé une correspondance parfaite avec un article existant sur le concept E-E-A-T de Google. Il comprend le sens caché de l’acronyme.
Un autre exemple est la redirection d’un vieil article de 2013 sur YouTube vers un contenu beaucoup plus récent et pertinent de 2022. Cela démontre la capacité du système à comprendre le contexte temporel. L’utilisateur atterrit sur la bonne page.
Openai ‘text-embedding-ada-002’ : une alternative viable ?
Le modèle `text-embedding-ada-002` d’OpenAI est une autre option populaire. Il offre une qualité jugée satisfaisante pour de nombreuses tâches. C’est souvent le choix par défaut.
Cependant, dans le cas de l’URL `/what-is-eat/`, le résultat était moins précis. Il a proposé une redirection vers un article plus générique sur le SEO, manquant la correspondance sémantique exacte. La nuance n’est pas détectée.
La qualité, bien que bonne, est considérée comme inférieure à celle de Google pour ce besoin.
L’équation économique : pourquoi payer plus cher
Google Vertex AI est environ trois fois plus cher qu’OpenAI. Le coût est d’environ 0,04 $ pour 20 000 URL, soit 2 $ pour un million d’URL. Ce coût reste très faible.
Le choix se porte sur Google malgré le surcoût. La raison est simple : le temps gagné en révision manuelle. On évite de repasser derrière la machine.
L’économie réalisée sur le temps de révision humaine justifie amplement l’investissement dans un modèle d’embedding plus performant, même s’il est plus cher à l’usage.
Les alternatives open-source : bert et llama
Pour ceux qui cherchent une solution gratuite, les modèles de Hugging Face comme BERT ou Llama sont une option. Ils peuvent être hébergés et exécutés sur sa propre infrastructure. C’est une liberté totale de gestion.
Le mot « gratuit » est à nuancer. Bien que les modèles soient libres, leur utilisation engendre des coûts de calcul (serveurs, GPU) et nécessite une expertise technique plus pointue pour la mise en place et la maintenance.
Intégration dans l’écosystème WordPress
Du fichier csv à l’action
Le fichier redirect_map.csv généré par le script constitue le livrable final de votre stratégie llm bases de données vectorielles wordpress seo. Il contient toutes les instructions de redirection prêtes à l’emploi. Ce document doit maintenant être importé dans WordPress pour devenir actif.
Cette étape est critique pour que les redirections 301 soient effectives et ne restent pas de simples données inexploitable. Vous évitez ainsi de perdre du trafic qualifié.
Le but consiste à traduire cette carte virtuelle en règles concrètes sur le serveur, sans intervention manuelle fastidieuse.
Le rôle des plugins de gestion de redirections
La méthode la plus pragmatique sur WordPress implique l’usage d’un plugin de gestion de redirections. Le marché offre de nombreuses solutions robustes pour éviter de manipuler le fichier .htaccess.
Prenons l’exemple du plugin « 301 Redirects – Redirect Manager ». Ces outils facilitent l’importation massive de redirections via un fichier CSV, ce qui correspond exactement à notre besoin d’automatisation. Cela sécurise le processus pour les sites à fort volume.
- Générer le fichier CSV final.
- Choisir et installer un plugin de gestion de redirections.
- Utiliser la fonction d’importation du plugin pour charger le CSV.
- Vider le cache et vérifier quelques redirections.
Vérification et monitoring post-déploiement
L’automatisation ne dispense pas d’une phase de vérification rigoureuse pour garantir la qualité du maillage. Il est conseillé de tester manuellement un échantillon de redirections pour valider la logique.
Après le déploiement, le monitoring continue de manière active. Il faut surveiller les rapports d’erreurs 404 dans la Google Search Console pour s’assurer qu’aucune nouvelle erreur n’apparaît et que les anciennes sont bien résolues.
La confiance n’exclut pas le contrôle, surtout lorsqu’il s’agit de préserver votre performance SEO.
Du correctif au proactif : le maillage interne sémantique
Repenser le maillage interne au-delà des ancres
Le maillage interne traditionnel repose excessivement sur l’optimisation des ancres de lien. C’est une approche limitée par la simple correspondance de mots-clés. L’intégration des llm bases de données vectorielles wordpress seo ouvre de nouvelles perspectives techniques.
L’idée est d’utiliser la proximité vectorielle pour suggérer les liens internes les plus pertinents. On ne lie plus des pages à cause d’un mot-clé commun, mais parce qu’elles traitent de sujets connexes, validés par l’IA.
Créer des clusters thématiques avec les vecteurs
En analysant les vecteurs de tous les articles d’un site, on peut identifier des clusters sémantiques précis. Ce sont des groupes de contenus qui parlent d’un même sujet global, détectés mathématiquement par les modèles de langage.
Cette technique, appelée « maillage interne vectoriel », permet de renforcer les cocons sémantiques de manière algorithmique. Elle assure que les pages d’un même univers thématique se lient fortement entre elles, créant une infrastructure WordPress techniquement irréprochable pour les moteurs de recherche et les IA.
Renforcer l’autorité sémantique pour le geo
Un maillage interne sémantiquement dense envoie un signal fort d’autorité thématique aux algorithmes. Cela est fondamental pour le GEO (Generative Engine Optimization), où la cohérence du fond prime sur la forme.
Les LLM cherchent des sources fiables et complètes pour construire leurs réponses. Un site bien structuré sémantiquement a plus de chances d’être perçu comme une autorité et d’être cité. L’impact de l’IA sur le trafic organique déplace la priorité vers la citation.
Vers un plugin wordpress de maillage intelligent
L’étape suivante logique est l’intégration de cette intelligence directement dans l’interface d’administration WordPress. L’idée est de développer un plugin de maillage interne qui utilise cette technologie pour assister les éditeurs en temps réel.
Un tel plugin pourrait, lors de la rédaction d’un article, suggérer automatiquement les 3 à 5 liens internes les plus pertinents sémantiquement. C’est d’ailleurs un projet exploré par Search Engine Journal pour le futur de leur plateforme.
L’impact stratégique : un SEO augmenté par l’IA
Consolider le « jus » seo et le budget de crawl
Le bénéfice le plus direct est la consolidation du classement SEO. En redirigeant systématiquement les URL mortes vers des pages pertinentes, on préserve l’autorité (le « jus de lien ») acquise au fil du temps.
De plus, en éliminant les culs-de-sac (404), on aide les robots des moteurs de recherche à explorer le site plus efficacement. Cela revient à mieux utiliser son budget de crawl, un enjeu pour les grands sites.
Une expérience utilisateur sans friction
Le SEO et l’expérience utilisateur (UX) sont intimement liés. Éradiquer les erreurs 404 est un gain direct pour le visiteur.
L’utilisateur qui suit un vieux lien ou un lien erroné est guidé en douceur vers l’information la plus proche de sa recherche initiale.
Cela réduit le taux de rebond, augmente le temps passé sur le site et renforce la confiance dans la marque.
L’ia comme amplificateur de compétences
Cette approche ne remplace pas le professionnel du SEO. Au contraire, elle le décharge des tâches répétitives et à faible valeur ajoutée.
Le temps ainsi libéré peut être réinvesti dans la stratégie, l’analyse et la créativité. L’IA devient un outil puissant pour mettre à l’échelle les efforts SEO et marketing.
L’expert SEO utilise l’IA comme copilote, pas comme un décideur autonome.
Les perspectives d’évolution de ces techniques
L’intégration de solutions llm bases de données vectorielles wordpress seo ne constitue qu’une première étape. Ces technologies vont continuer de s’affiner pour une automatisation accrue.
- Les bénéfices stratégiques principaux : Amélioration de l’UX en éliminant les pages d’erreur.
- Consolidation du SEO par la préservation de l’autorité.
- Optimisation du budget de crawl des moteurs.
- Scalabilité pour gérer des millions de pages sans effort manuel.
L’intégration des LLM et des bases vectorielles révolutionne la gestion des redirections 301 sur WordPress. Cette automatisation préserve le budget de crawl et optimise l’expérience utilisateur face aux erreurs 404.
Au-delà du gain de temps technique, cette stratégie renforce durablement l’autorité sémantique du site pour le SEO moderne.
FAQ
Comment les LLM interagissent-ils avec les bases de données vectorielles pour le SEO ?
Les modèles de langage (LLM) transforment les contenus textuels et les URL en représentations numériques appelées embeddings. Ces vecteurs capturent le sens sémantique profond des pages, bien au-delà des simples mots-clés. Ils constituent l’ADN numérique du contenu.
La base de données vectorielle, telle que Pinecone, stocke et indexe ces millions de vecteurs. Elle permet d’effectuer des recherches de similarité ultra-rapides pour associer une URL obsolète à la page active la plus pertinente sémantiquement.
Quel est le rôle d’un LLM dans l’analyse sémantique des redirections ?
Dans ce processus d’automatisation, le LLM n’a pas pour fonction de rédiger du texte. Son rôle est strictement analytique : il convertit le langage naturel en données mathématiques exploitables par la machine.
Cette conversion permet de comprendre l’intention derrière une URL, même si celle-ci est mal formée ou incomplète. Le modèle identifie les concepts similaires entre une ancienne ressource et le catalogue actuel pour proposer la meilleure redirection 301.
Quelle intelligence artificielle privilégier pour l’automatisation des redirections ?
Le modèle text-embedding-005 de Google Vertex AI démontre une efficacité supérieure pour les tâches de recherche et de similarité. Il surpasse souvent des alternatives comme text-embedding-ada-002 d’OpenAI en termes de précision contextuelle.
Bien que le coût de Google Vertex AI soit plus élevé, sa capacité à trouver des correspondances exactes justifie l’investissement. Il réduit considérablement le temps humain nécessaire à la vérification des correspondances proposées.
Comment optimiser la gestion technique du SEO sur WordPress avec cette méthode ?
L’optimisation repose sur l’importation massive d’un fichier CSV, généré par le script d’IA, directement dans l’interface WordPress. Des plugins comme « 301 Redirects – Redirect Manager » facilitent cette intégration en traitant les instructions par lots.
Cette approche permet de corriger des milliers d’erreurs 404 simultanément sans intervention manuelle ligne par ligne. Elle préserve le budget de crawl des moteurs de recherche et consolide l’autorité du domaine.
Qu’est-ce que le GEO (Generative Engine Optimization) dans ce contexte ?
Le GEO désigne l’optimisation des contenus pour maximiser leur visibilité dans les réponses générées par les intelligences artificielles. L’utilisation de vecteurs pour structurer le maillage interne renforce la cohérence sémantique du site.
Une architecture de site fondée sur des clusters thématiques vectoriels envoie un signal fort d’autorité. Cela augmente la probabilité que le contenu soit cité comme source fiable par les assistants conversationnels et les nouveaux moteurs de recherche.



