

L’essentiel à retenir : le classement Perplexity repose sur un système hybride alliant filtrage algorithmique L3 et curation manuelle de domaines d’autorité. La fraîcheur est décisive, la visibilité chutant après seulement trois jours. Pour intégrer les réponses génératives, le contenu exige une structure sémantique optimisée pour les LLM. Pour en savoir plus: Contactez- nous!
L’incertitude autour du ranking perplexity sources complique l’adaptation des stratégies SEO face aux exigences des nouveaux moteurs de réponse. Cette analyse examine les spécificités techniques de l’algorithme, du filtrage par le système L3 à l’impact immédiat de la fraîcheur de l’information. L’étude de ces variables, dont l’autorité de domaine et l’engagement utilisateur, fournit les méthodes pour intégrer les citations générées par l’intelligence artificielle.
Les mécanismes cachés du classement Perplexity
La plupart des experts SEO se concentrent sur les mots-clés, mais ce moteur fonctionne différemment. L’analyse technique menée par Metehan Yesilyurt a mis en lumière 59 facteurs souvent ignorés par les professionnels.
Ces critères révèlent comment l’IA sélectionne réellement ses informations avant de générer une réponse. Comprendre le ranking perplexity sources demande de regarder sous le capot de l’algorithme.
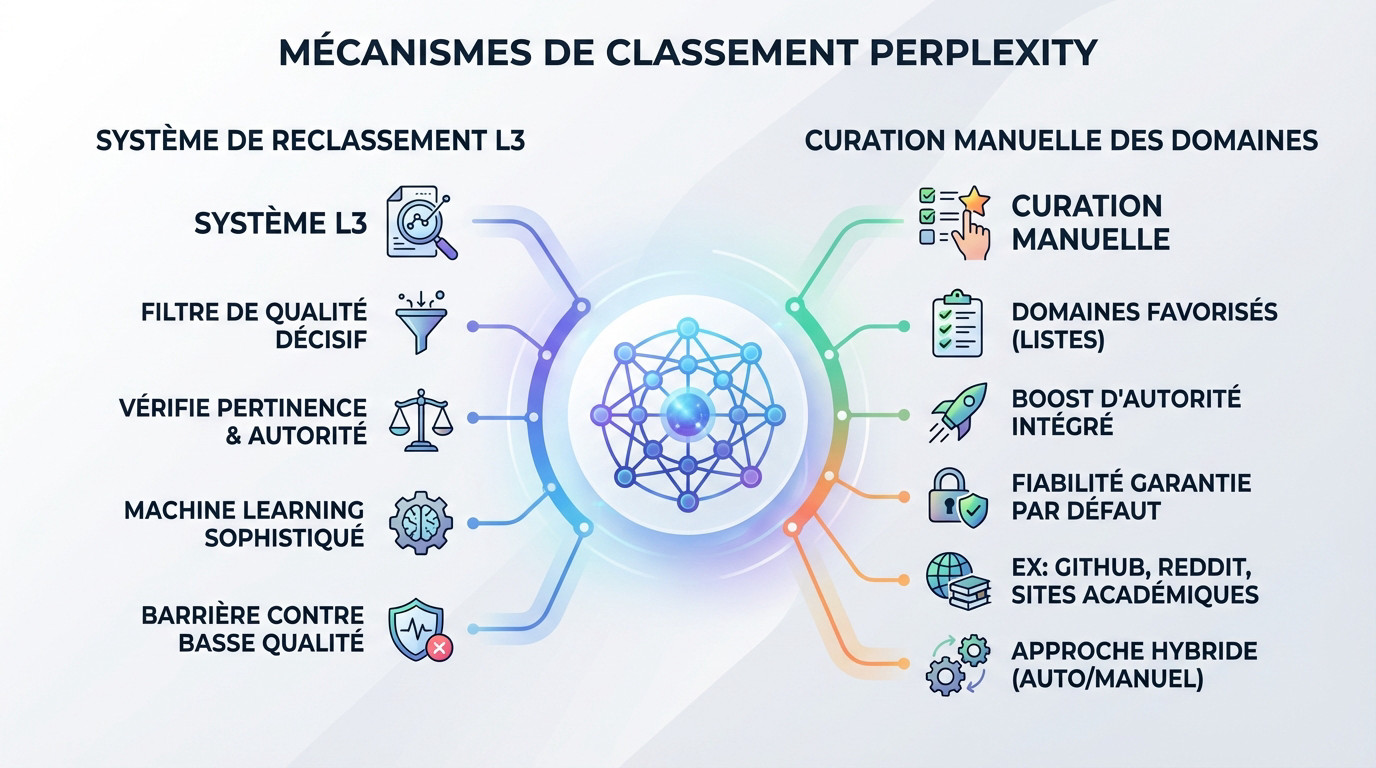
Le système de reclassement L3 : un premier filtre décisif
Perplexity ne se contente pas d’une indexation classique des pages web. Il active un système de reclassement L3 spécifique pour le traitement des données. Cette couche vérifie rigoureusement les recherches d’entités.
Ce mécanisme agit comme un filtre de qualité impitoyable sur les résultats. Il évalue l’autorité thématique avant même de citer une source dans la réponse. C’est une différence fondamentale avec le fonctionnement du SEO traditionnel.
Ce modèle de machine learning sophistiqué bloque l’entrée aux contenus médiocres. Seule une pertinence technique avérée permet de franchir cette barrière.
La curation manuelle : des domaines favorisés d’office
L’algorithme ne décide pas de tout en totale autonomie. Des ingénieurs maintiennent des listes de domaines spécifiques pour orienter les réponses. Ces sites sont curés manuellement par les équipes internes.
Ces plateformes reçoivent un « « boost » d’autorité immédiat dans le calcul du classement. Le moteur leur accorde une confiance par défaut pour garantir la fiabilité. Cela sécurise la pertinence des informations fournies.
Cette approche hybride, mi-automatique mi-manuelle, s’avère centrale dans la stratégie de sélection des sources. Voici les types de plateformes souvent privilégiés :
- GitHub pour les solutions techniques et le code.
- Reddit pour les discussions et retours communautaires.
- Les sites académiques reconnus pour la validation scientifique.
Autorité et fraîcheur : les piliers de la confiance
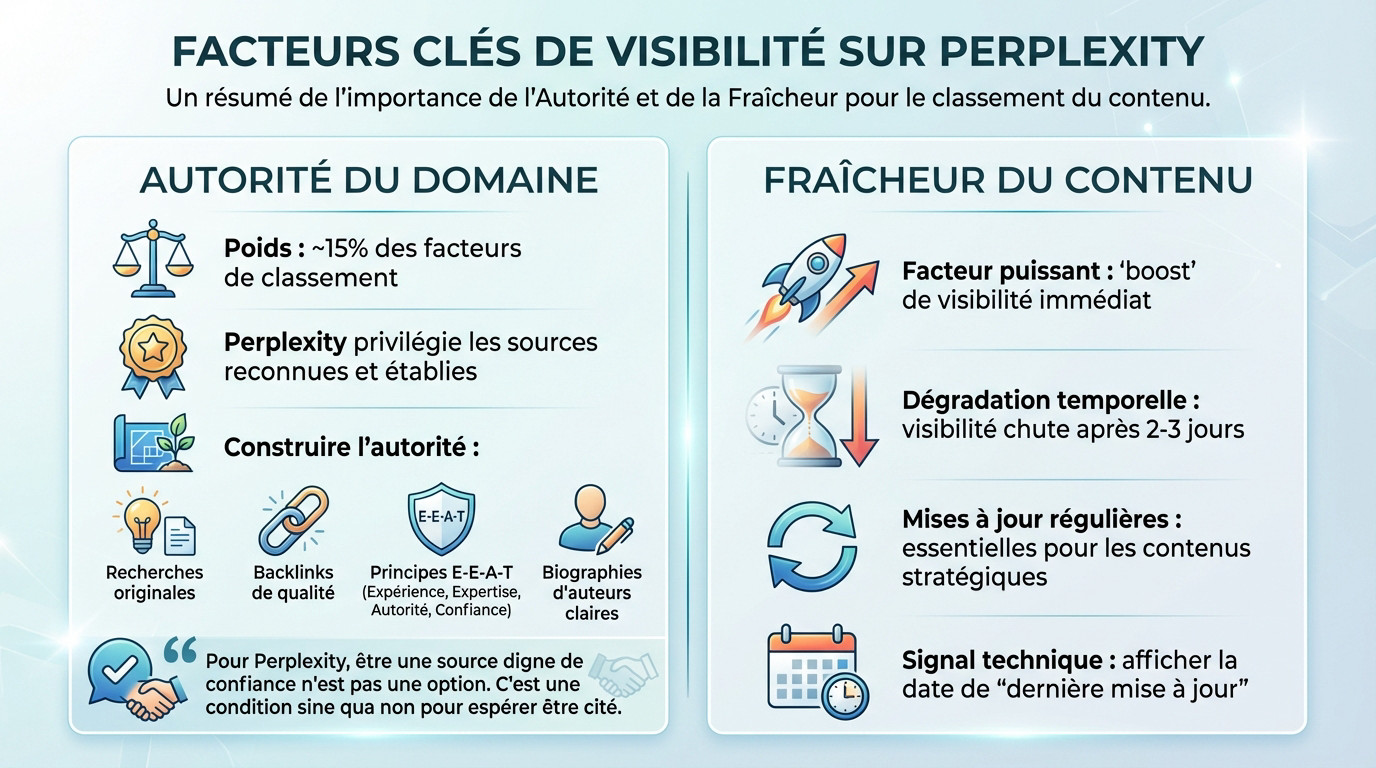
L’autorité du domaine, un signal de crédibilité non négociable
L’autorité du domaine pèse lourd, représentant environ 15 % des facteurs de classement. Pour optimiser le ranking perplexity sources, le moteur privilégie systématiquement les sources reconnues et établies. Les nouveaux sites peinent souvent à percer face à cette barrière à l’entrée.
Construire cette légitimité exige une stratégie précise. Il faut publier des recherches originales et capter des backlinks de haute qualité. L’application stricte des principes E-E-A-T (Expérience, Expertise, Autorité, Confiance) avec des biographies d’auteurs claires devient vitale.
Pour Perplexity, être une source digne de confiance n’est pas une option. C’est une condition sine qua non pour espérer être cité dans ses réponses génératives.
La dégradation temporelle et l’obsession de la fraîcheur
La fraîcheur du contenu constitue l’un des facteurs les plus puissants de l’algorithme. Un contenu nouveau ou récemment mis à jour reçoit un « boost » de visibilité immédiat. L’IA détecte la moindre modification et récompense l’actualité de l’information.
Ce mécanisme cache une réalité brutale : la dégradation temporelle. La visibilité d’un contenu commence à chuter significativement après seulement 2 à 3 jours sans modification. Pour rester visible, les contenus stratégiques nécessitent des mises à jour très régulières.
L’affichage technique de la date de « dernière mise à jour » est indispensable. Ce signal aide le LLM à évaluer la récence de l’information présentée. Sans ce marqueur, l’algorithme risque de juger la donnée obsolète.
Structurer pour la citation : le rôle du format et de l’engagement
La pertinence sémantique et le formatage pour les llm
Comprendre le ranking perplexity sources exige une approche « RAG-friendly ». La pertinence sémantique constitue le socle technique de cette visibilité. Le contenu doit satisfaire une intention précise sans ambiguïté.
L’IA favorise des structures spécifiques pour extraire ses réponses. Voici les formats qui augmentent vos chances de citation :
- Des définitions concises en début de paragraphe.
- Des listes à puces ou numérotées logiques.
- Des sections Q&A claires et directes.
- Les informations critiques placées en haut.
Les données structurées via le balisage Schema pèsent 10% dans l’équation. Elles guident le LLM vers l’intention du contenu. C’est un pilier de l’optimisation pour les moteurs génératifs (GEO) souvent ignoré.
L’engagement utilisateur comme validation de la valeur
L’algorithme ne se contente pas de lire le texte. L’engagement utilisateur sert de validation externe de la pertinence. Perplexity traque le temps passé, le défilement et les partages sociaux.
Les données techniques révèlent une exigence de performance immédiate. Le contenu doit générer un volume d’impressions rapide. Il faut impérativement un taux de clics (CTR) d’au moins 4,2% dans les 30 premières minutes.
Dans l’écosystème de Perplexity, être cité est le nouveau clic. L’engagement des utilisateurs est la preuve que votre contenu mérite cette citation.
Facteurs avancés et signaux à éviter
Au-delà des bases techniques, certains leviers spécifiques et des erreurs fatales déterminent si l’IA vous cite ou vous ignore totalement.
L’effet YouTube et le réseautage de contenu
Perplexity ne se limite pas au texte, il adore la vidéo. L’algorithme utilise massivement cette plateforme comme gage de fiabilité, créant un puissant « effet YouTube ». Si vous produisez des tutoriels ou des explications visuelles, vous devenez une source prioritaire.
Mais ne restez pas isolé sur votre site. Il faut occuper le terrain sur Reddit ou LinkedIn, car ce réseautage de contenu nourrit directement le moteur. Ces stratégies pour la recherche générative sont désormais vitales pour maîtriser le ranking perplexity sources.
La catégorisation thématique et les signaux négatifs
Votre sujet dicte votre plafond de verre. Des domaines comme l’IA ou le marketing reçoivent un multiplicateur de classement, boostant artificiellement leur visibilité. À l’inverse, Perplexity bride algorithmiquement les thématiques jugées moins « nobles » comme le divertissement.
La confiance technique n’est pas une option. Sans un protocole HTTPS strict et une conformité RGPD impeccable, le moteur vous écarte immédiatement.
Voici les signaux négatifs qui détruisent votre score :
- Contenu dupliqué ou redondant.
- Score de qualité inférieur à 0,75.
- Expérience utilisateur désastreuse.
- Excès de publicités bloquant la lecture.
Maîtriser le référencement sur Perplexity impose une stratégie hybride. L’autorité du domaine, la fraîcheur de l’information et l’engagement utilisateur constituent les piliers majeurs de cette visibilité.
L’optimisation pour les moteurs génératifs (GEO) complète désormais le SEO classique. Structurer le contenu pour la citation garantit une présence durable dans les réponses de l’IA.
FAQ
Comment le système de reclassement L3 de Perplexity sélectionne-t-il les sources ?
Perplexity utilise un mécanisme de reclassement nommé L3, basé sur le machine learning. Ce système intervient après la récupération initiale pour filtrer les résultats, spécifiquement lors des recherches d’entités ou de concepts. Il évalue la pertinence thématique et l’autorité avant toute génération de réponse.
Ce filtre agit comme une barrière de qualité stricte. Si les sources récupérées n’atteignent pas le seuil d’exigence du système L3, l’algorithme écarte l’ensemble des résultats. Cette approche privilégie la fiabilité de l’information sur la simple correspondance de mots-clés.
Quels sont les principaux facteurs de classement sur Perplexity AI ?
L’autorité du domaine et la fraîcheur de l’information constituent des critères prédominants. L’algorithme accorde un « boost » de visibilité immédiat aux contenus récents, mais applique une dégradation temporelle rapide après 2 à 3 jours. L’autorité représente environ 15 % du poids total dans le classement.
L’engagement utilisateur joue également un rôle critique dans l’évaluation algorithmique. Des métriques comme le temps de lecture et le taux de clics signalent la valeur du contenu. De plus, une curation manuelle favorise certains domaines reconnus comme GitHub ou LinkedIn.
Comment optimiser son contenu pour apparaître dans les réponses de Perplexity ?
La structuration des données est essentielle pour faciliter l’extraction par les LLM. L’utilisation du balisage Schema et de formats clairs, tels que les listes à puces ou les sections Q&A, améliore la lisibilité pour l’IA. Ces optimisations techniques augmentent la probabilité d’être cité.
Il est crucial de générer un engagement fort dès la publication. Un taux de clics (CTR) supérieur à 4,2 % dans les 30 premières minutes envoie un signal positif puissant. Les sujets liés à l’IA, la science ou le marketing bénéficient par ailleurs de multiplicateurs de classement avantageux.
Perplexity cite-t-il systématiquement les sources qu’il utilise ?
La citation des sources est un mécanisme fondamental du moteur de réponse. La capacité d’un contenu à être cité influence jusqu’à 35 % de ses chances d’inclusion dans une réponse générée. L’algorithme privilégie les textes qui permettent une attribution précise de l’information.
Un score de qualité de 0,75 est-il suffisant pour être référencé?
Un score de qualité de contenu de 0,75 constitue le seuil minimal requis pour accéder aux meilleurs emplacements de réponse. Ce métrique interne évalue la densité informative et la fiabilité du texte. En dessous de ce chiffre, la visibilité du contenu dans les réponses génératives chute drastiquement.



