

L’analyse de logs fait partie des outils d’audit de site web les plus avancés pour peaufiner une stratégie SEO. Il permet notamment de savoir comment les moteurs de recherche explorent un site web, quelles sont les pages les plus crawlées, à quelle fréquence les bots crawlent les différents types de pages et ressources, etc…
Cet outil relativement technique est néanmoins indispensable pour savoir exactement tout ce qui se passe sur un domaine, à quel moment et sur quelle page. Grâce à des datas très fines et impossibles à obtenir autrement, vous pouvez actionner avec une précision chirurgicale des leviers d’optimisation complexes sur le budget et la fréquence de crawl, le maillage interne, les URLs mal exploitées, etc. sans commettre d’erreurs.
À travers ce case study détaillé, nous mettrons en lumière la méthodologie d’une analyse de logs et en présenterons les avantages stratégiques, non sans évoquer les risques d’une mauvaise interprétation. Vous trouverez également nos recommandations d’outils pour mener à bien une analyse de logs en 2025.
Rappel : quelle est la différence entre le crawl SEO classique et une analyse de logs ?
Le crawl SEO classique consiste à utiliser un robot crawler afin de parcourir un site web en partant de la page d’accueil. À l’instar des bots des moteurs de recherche dont il simule le parcours, il visite toutes les pages accessibles via les liens internes. Cette reproduction du crawl des Googlebots et autres user-agents pour tester la structure interne du site reste néanmoins très incomplète.
À cet égard, l’analyse de logs va beaucoup plus loin, puisqu’elle consiste à récupérer, sur une période déterminée, toutes les interactions ayant réellement eu lieu sur le site (chaque fois que le serveur répond à une requête d’utilisateur ou de robot) dont une trace a été conservée dans un fichier journal.
En effet, chaque requête ayant suscité une réponse du serveur figure sur le fichier de log. Il en ressort une liste dont chaque ligne représente un « hit » avec plusieurs variables utiles telles que :
- l’adresse IP de la requête ;
- la date et l’heure précises de la demande ;
- le protocole de la requête (GET/POST) ;
- l’URL demandée (chemin et paramètres) ;
- le code de réponse HTTP (200, 301, 404, 500…) ;
- le user-agent (navigateur ou bot) ;
- le temps de réponse du serveur ;
- le referrer (page d’origine de la requête) ;
- le volume de données transférées.
L’analyse de logs permet donc de savoir exactement quelles pages ont été visitées, quand, par quel robot, et avec quel résultat — y compris des pages orphelines, non maillées ou supprimées, lesquelles échappent à un crawl classique.
Nota Bene : le format et contenu des fichiers de logs changent selon le serveur. Il est possible de les personnaliser afin d’en récupérer les données qui nous intéressent.
Pourquoi l’analyse de logs est-elle cruciale pour le SEO ?
Puisque l’analyse de logs offre une vision exhaustive de toute l’activité réelle ayant lieu sur un site web, on peut en tirer des informations stratégiques très pointues, à savoir :
- comment Googlebot explore réellement votre site : répartition du budget crawl, fréquence de passage des bots d’indexation, etc. ;
- l’impact des filtres et paramètres d’URL, qui peuvent générer une multitude de pages dynamiques peu pertinentes pour le SEO ou dupliquées. Sans valeur ajoutée pour le SEO, celles-ci peuvent consommer du budget crawl et impacter négativement le crawl des pages stratégiques ;
- les codes réponses rencontrés par les bots et notamment les 4XX, 5XX, etc… ;
- les chaines de redirections (très utiles lors d’une refonte) ;
- les spider trap ou piège à robots dans des boucles de redirections infinies (gaspillage de budget crawl assuré)
- l’efficacité du maillage interne ;
- les écarts entre le crawl et le trafic réel, pour identifier les pages sur-investies par les bots mais peu performantes, ou inversement,
- l’identification de fenêtres de crawl privilégiées, utiles pour planifier les mises à jour ou la publication de contenus.
En croisant les données de logs avec d’autres sources (trafic, Search Console, crawl), il devient alors possible de prioriser les actions SEO avec une grande précision, en identifiant les pages réellement stratégiques, les zones d’inefficacité du site, mais également les opportunités d’optimisation du maillage, de l’indexation ou de la structure technique.
Quels sont les risques d’une mauvaise analyse de logs sur les enjeux business ?
Une analyse de logs approximative ou biaisée (données partielles ou mal croisées) peut mener à des actions contre-productives. Aussi a-t-on déjà observé des impacts lourdement négatifs sur le business digital de certains acteurs, comme :
- la suppression ou la désindexation de pages à fort trafic suite à une mauvaise identification des pages orphelines ;
- le détournement du budget de crawl vers des pages inutiles (filtres, paramètres, anciennes versions), au détriment des pages à fort potentiel ;
- la non-correction de problèmes techniques majeurs (boucles de redirection, erreurs 404 massives) pouvant entraîner une chute brutale du positionnement dans les SERP ;
- des migrations ou des refontes de site catastrophiques.
Bref, rien de tel pour perdre du trafic organique et le chiffre d’affaires qui va avec.
Pourquoi confier l’analyse de logs à un expert ?
Interpréter la somme astronomique d’informations (jusqu’à plusieurs millions de lignes par jour !) recueillie sur les fichiers log est donc une gageure réservée aux professionnels du SEO. En effet, les représentants du métier disposent d’outils spécifiques pour extraire et isoler les bons signaux via diverses manipulations :
- filtrer les bonnes données des fichiers bruts ;
- croiser les logs avec d’autres sources (crawl, analytics, Search Console) ;
- segmenter les URL par typologie ou thématique afin d’identifier les zones du site sur- ou sous-crawlées ;
- identifier et valider les user-agents pertinents, en isolant notamment le comportement des bots d’indexation (Googlebot, Bingbot…) ;
- reconnaître les schémas d’exploration anormaux (pics de crawl, crawl sur des pages désindexées ou inutiles) ;
- visualiser ces données sous forme de tableaux, de courbes ou de heatmaps, pour faciliter la prise de décision.
Sachant que même en ayant détecté les bonnes problématiques, savoir arbitrer sur les solutions à appliquer (noindex, blocage, obfuscation, canonical, modification du maillage…) relève d’une expertise et d’une expérience avancée pour garantir la fiabilité des conclusions.
Étude de cas : analyse de logs sur site e-commerce de cartes et faire-part personnalisables à catalogue dynamique
Le cas pratique qui va nous occuper aujourd’hui concerne le site e-commerce d’un acteur du secteur de la papèterie voulant éprouver sa propre stratégie de référencement naturel. Pour cette fois, nous ne citerons pas le nom du client, car l’analyse de logs touche à des données confidentielles. Quoi qu’il en soit, tout ce qui importe, c’est de savoir que le site se caractérise par un fort catalogue dynamique.
Quelles sont les particularités et les enjeux d’un catalogue dynamique en e-boutique ?
Un site à catalogue dynamique se reconnaît par son nombre conséquent de pages (entre plusieurs milliers et plusieurs millions). Une grande partie de ces pages est générée automatiquement en fonction de critères comme :
- les filtres (couleur, taille, prix…),
- les combinaisons de produits,
- les tris (du plus cher au moins cher, nouveautés, etc.)…
… et toutes sortes de paramètres d’URLs comme la catégorie, la pagination, le tracking, etc.
Nota Bene : un paramètre d’URL (ou query string) est une partie variable qui s’ajoute à la fin d’une URL pour transmettre des informations spécifiques, souvent après un point d’interrogation ? Exemple simple : https://www.exemple.com/produits?categorie=papeterie&tri=prix_asc contient le paramètre categorie (valeur “papeterie”) et le paramètre tri (valeur “prix_asc”).
Objectifs et enjeux SEO de la mission
L’objectif de la mission était d’évaluer et d’optimiser la stratégie SEO technique, notamment sur la gestion des paramètres d’URL, du maillage interne et la priorisation des contenus stratégiques. La focale devait également être portée sur le budget crawl de Google, afin d’identifier de nouveaux axes d’optimisation.
Ces leviers devaient notamment aboutir à une meilleure indexation des pages stratégiques, une circulation optimale du PageRank, et un trafic organique en hausse. Nous avons donc suivi un plan en 7 étapes avant de dresser une roadmap à partir des recommandations envisagées.
Étape 1 : Collecte et préparation des fichiers de log
Afin de disposer d’une base de données fiable et représentative, l’idéal est de disposer de la journalisation des logs, c’est-à-dire la récolte automatisée des données, laquelle permet de comparer des périodes longues et de voir l’évolution du comportement des bots selon la période.
Nous avons donc procédé à la récupération des logs serveurs sur une période de plusieurs mois. En effet, un échantillon trop restreint ne permettrait pas de cerner d’éventuels pics ou creux liés à des mises à jour techniques, des pics saisonniers ou des campagnes marketing.
Mais avant même de commencer à analyser les logs, il convient de vérifier s’ils sont bel et bien exploitables, à savoir ni partiels, ni tronqués, ni corrompus, quelle qu’en soit la cause :
- logging trop léger ;
- format mal structuré incompatible avec les standards des outils SEO ;
- absence de champs clés comme le user-agent ou le code HTTP ;
- accès restreint aux fichiers access.log ;
- logs supprimés trop vite sans sauvegarde.
Ce genre de problème peut survenir à cause d’une mauvaise configuration du serveur ou d’un manque de coordination avec l’hébergeur. Si tel avait été le cas, il aurait d’abord fallu pallier les défauts du logging avant de recueillir un nouvel échantillon. Cette fois, les logs sont bien assez exhaustifs, et nous les importons dans un outil d’analyse dédié (nous vous reportons à la section outils pour de plus amples détails).
Étape 2 : Segmentation et catégorisation des URLs
Comment segmenter des données d’URLs ? Selon trois axes majeurs : la structure d’URL, la typologie des pages et leur sémantique/thématique.
Segmentation par type d’URL
Nous avons commencé par regrouper les URLs en grandes familles techniques, lesquelles correspondent peu ou prou à une étape du parcours utilisateur :
- Pages produits : chaque produit personnalisable dispose de sa propre URL (ex : /cartes/naissance/jules-bleu/).
- Pages catégories : (ex : /cartes/anniversaire/).
- Pages de pagination : générées automatiquement lorsqu’une catégorie contient plusieurs pages de résultats (ex : /cartes/anniversaire?page=3).
- Pages dynamiques issues de filtres : variations d’URL générées par des tris ou des filtres (ex : couleur, format, orientation, ex : /cartes/anniversaire?color=bleu&format=portrait).
Vu le degré de personnalisation des cartes proposé par la marque, l’on peut assez aisément se figurer le nombre conséquent de pages dynamiques explorables produites par le site. Il était donc préférable de nous y attarder.
Identification et qualification des paramètres d’URL
Pour contenir et gérer la prolifération des URLs dynamiques liées aux filtres ou aux campagnes marketing, nous avons dressé un inventaire exhaustif des paramètres d’URL actifs : ?color=, ?format=, ?utm_source=, ?sessionId=, etc.. Nous en avons ensuite déduit leur impact SEO, afin de déterminer une règle pour chaque paramètre :
- génère-t-il du contenu dupliqué (ex : tri par prix, pagination, etc.) – sujet à canonicalisation ?
- a-t-il assez de valeur SEO pour être indexé – y placer une balise “noindex” ?
- gaspille-t-il du budget crawl – à bloquer via le fichier robots.txt (ex : filtres peu utilisés, sessions, paramètres techniques) ?
Conjointement au prisme technique, nous avons repassé l’ensemble du site sous l’angle sémantique.
Segmentation thématique des pages
Pour mieux visualiser la performance de certaines zones du site, nous avons dû procéder à un classement par famille de produits (cartes d’anniversaire, faire-part de mariage, cartes de vœux, cartes de remerciement, etc.)
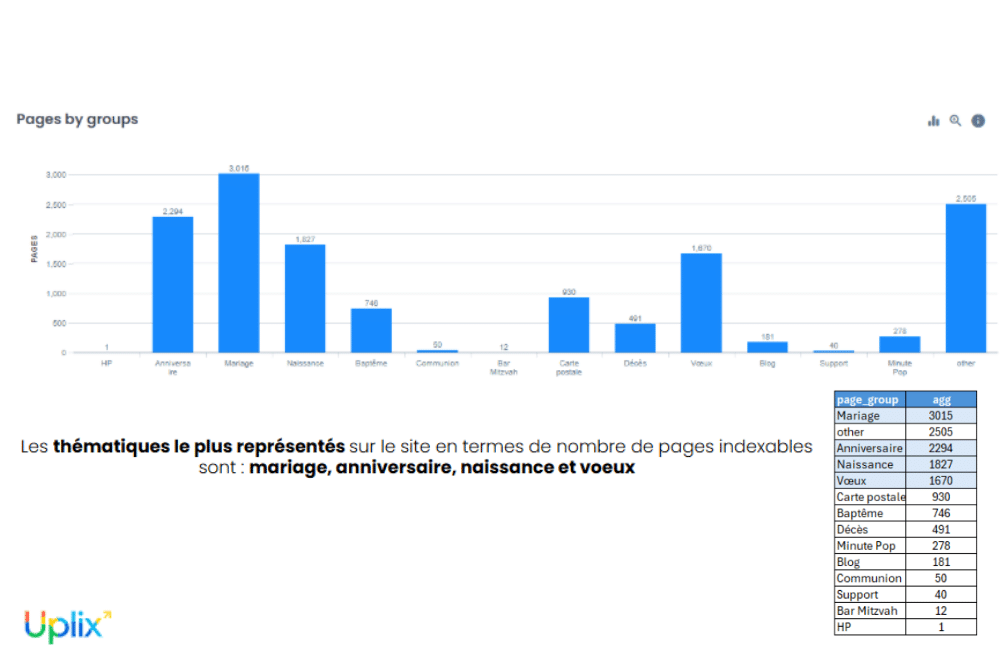
Cette segmentation permettra, un peu plus tard, de repérer des zones produits sur-crawlées par Googlebot, au détriment d’autres familles plus stratégiques, c’est-à-dire des pages peu explorées mais à fort potentiel de conversion (ex : cartes saisonnières non explorées à l’approche d’un marronnier).
Nota Bene : de façon générale, toute cette cartographie permet une meilleure priorisation des actions techniques (désindexation, canonisation, obfuscation, etc.), un suivi régulier des dérives (multiplication de pages filtrées peu utiles), une lecture plus claire de l’impact des campagnes payantes sur la création d’URLs parasites (paramètres d’AdWords ou de tracking).
Étape 3 : Analyse des codes de réponse serveur (200, 404, 301, etc.)
L’analyse des logs permet d’observer comment chaque page du site répond aux sollicitations des bots via les codes HTTP : 200 (OK), 301 (redirection permanente), 404 (non trouvé), 500 (erreur serveur), etc. Ces indicateurs sont essentiels pour évaluer la l’accessibilité du site et l’efficacité de son crawl.
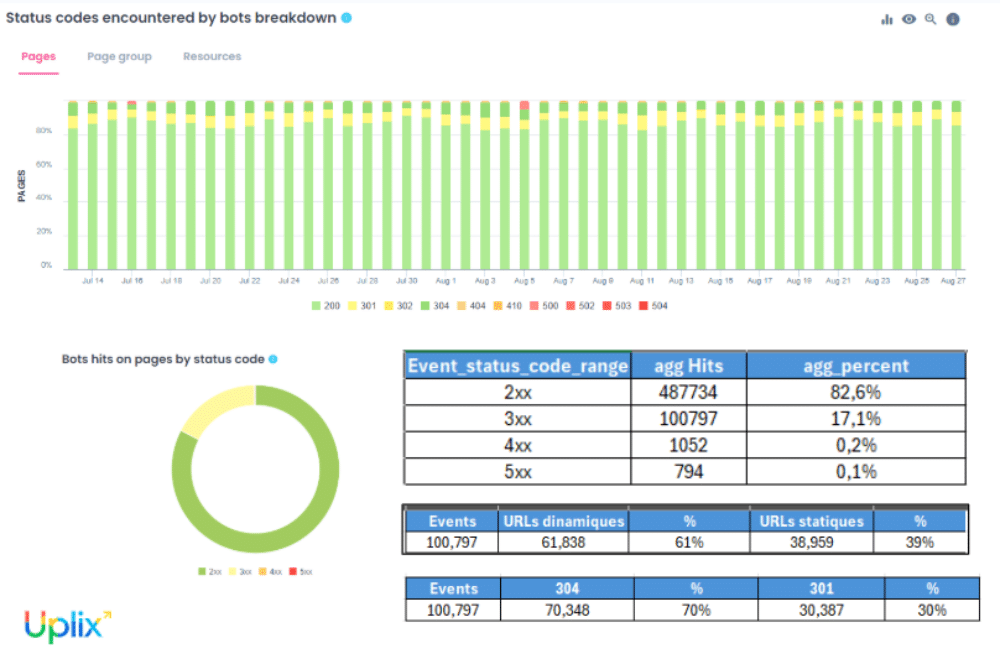
À titre d’exemple :
- quelques erreurs 404 ont été détectées sur d’anciennes pages de collections saisonnières (ex. : cartes de vœux 2023) supprimées sans redirection. Résultat : Googlebot gaspille du budget sur des pages qui n’existent plus.
- des erreurs 500 ponctuelles ont été relevées sur des pages de prévisualisation personnalisées, générées à la volée par un moteur de rendu. Cela trahit un manque de robustesse côté serveur.
- des chaînes de redirection ont été repérées entre des filtres de tri ou d’affichage (ex. : /cartes?sort=recent redirige vers /cartes?sort=recent&lang=fr, qui elle-même redirige vers une URL canonique).
Dans notre cas, il n’y avait pas une grosse problématique concernant les codes réponses.Cela étant, ce type d’analyse peut s’avérer très intéressante sur des sites qui ont des problématiques de 404 remontées par la Google Search Console, car l’outil de Google ne fournit qu’un échantillon des erreurs 404. Si l’on souhaite avoir l’intégralité des 404, les logs représentent la solution la plus complète.
Étape 4 : Comparaison entre structure du site et crawl
Après le classement des pages par typologie, par thématique et par code de réponse HTTP, il était temps de se pencher sur le crawl par Googlebot. Pour ce faire, il suffit de croiser les données issues des fichiers de logs avec la cartographie des URLs réalisée en amont. De cette manière, nous avons très distinctement révélé le ratio entre pages crawlées et non crawlées sur le site.
L’analyse des pages non crawlées nous a permis d‘identifier des problématiques techniques qui empêchaient le crawl, notamment concernant les pages de pagination. Ce constat a pu aboutir à des recommandations rapides afin de régler une problématique très sensible sur un site e-commerce. En effet, si les bots ne peuvent pas crawler les pages de pagination, ils ne peuvent pas non plus crawler les produits listés sur ces pages !
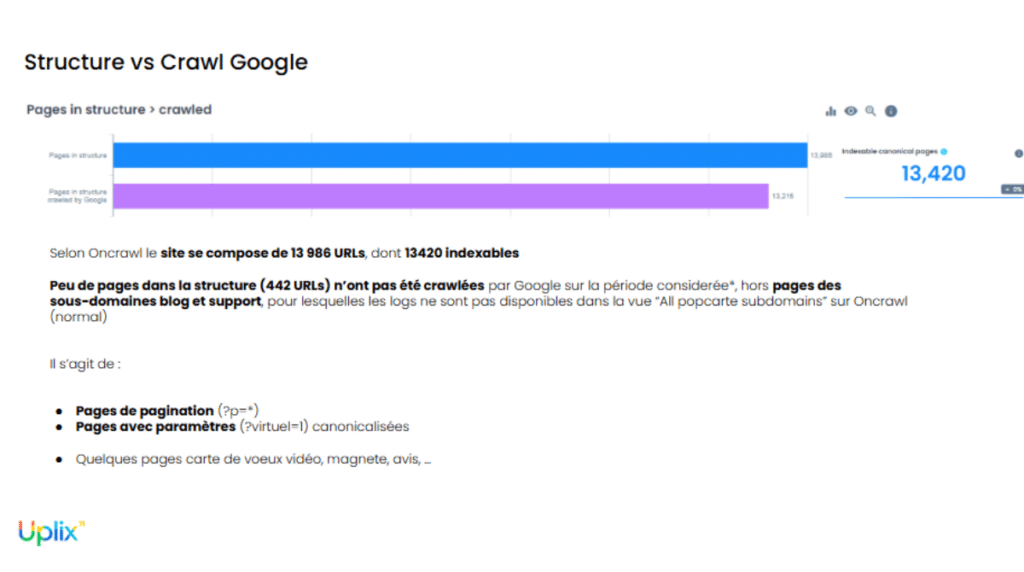
Ces observations sont importantes pour une première identification des problématiques ciblées dans le temps et par type de pages.
Étape 5 : Croisement des données de crawl et de trafic
Cette étape est charnière, puisqu’elle consiste à croiser toutes les données issues des analyses de logs (volume de hits par typologie et par thématique, codes de réponse HTTP, pages orphelines, distribution du budget crawl, fréquence et distribution temporelle du passage des bots…) avec les mesures d’autres outils tels que la Google Search Console, Google Analytics ou Matomo.
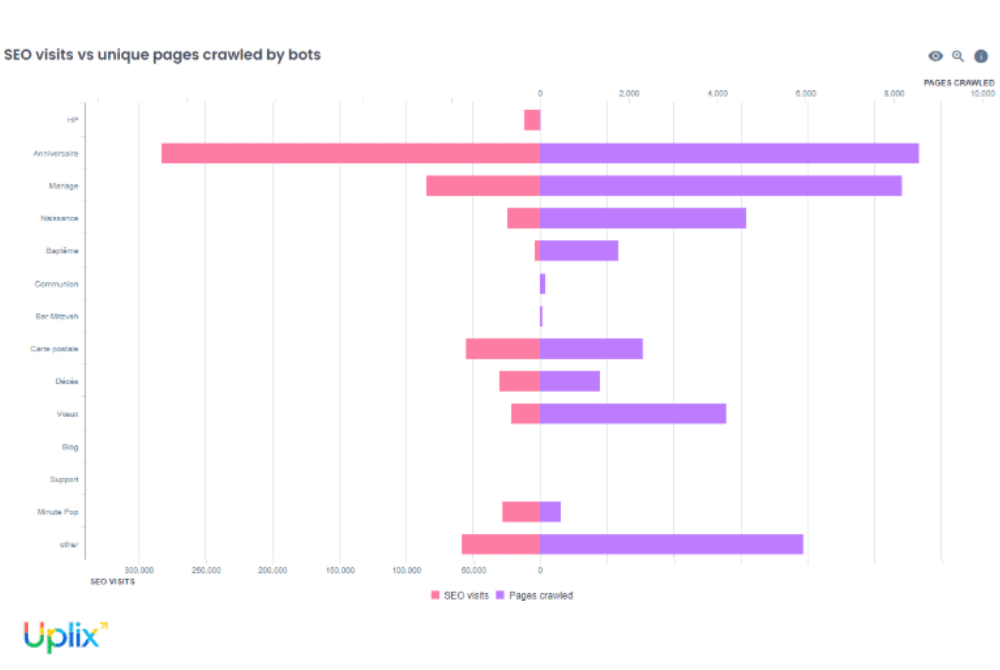
Ainsi, les performances réelle (trafic organique, sessions, clics, impressions) ont notamment été mises en balance avec les données de crawl, avec une attention particulière accordée au ratio crawl/visites pour chaque typologie de page (produits, catégories, blog, pages filtrées, etc.).
- les pages consommant beaucoup de budget crawl sans générer de trafic, souvent des pages à faible intérêt business comme certains filtres, les pages institutionnelles ou les contenus à faible valeur ajoutée ;
- les pages performantes sous-explorées par les bots, comme certaines fiches produits ou des contenus à fort potentiel commercial.
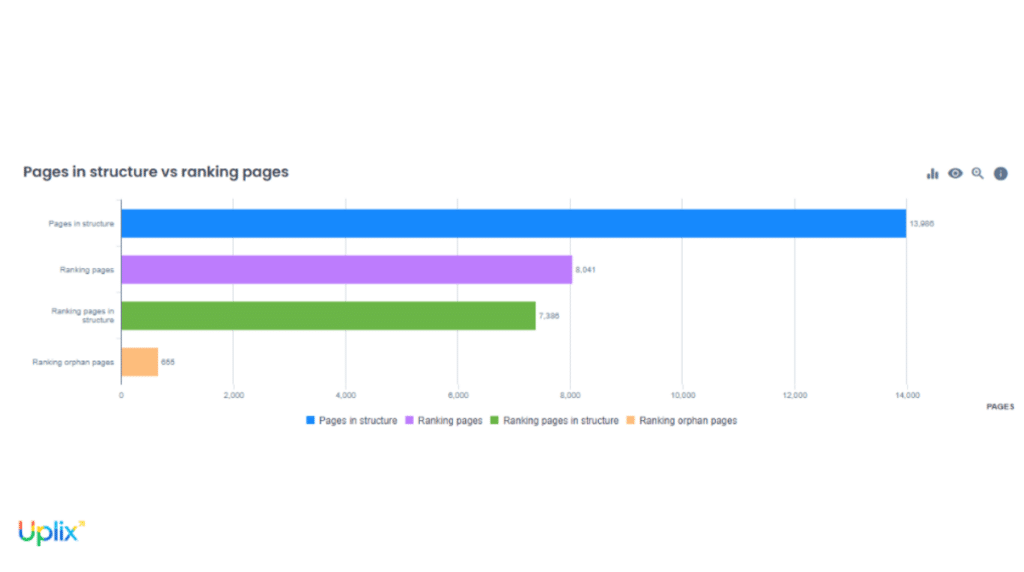
Les premières sont candidates à la désindexation (via une balise noindex, par exemple) ou à la dépriorisation (retrait ou obfuscation de liens internes vers l’URL concernée).
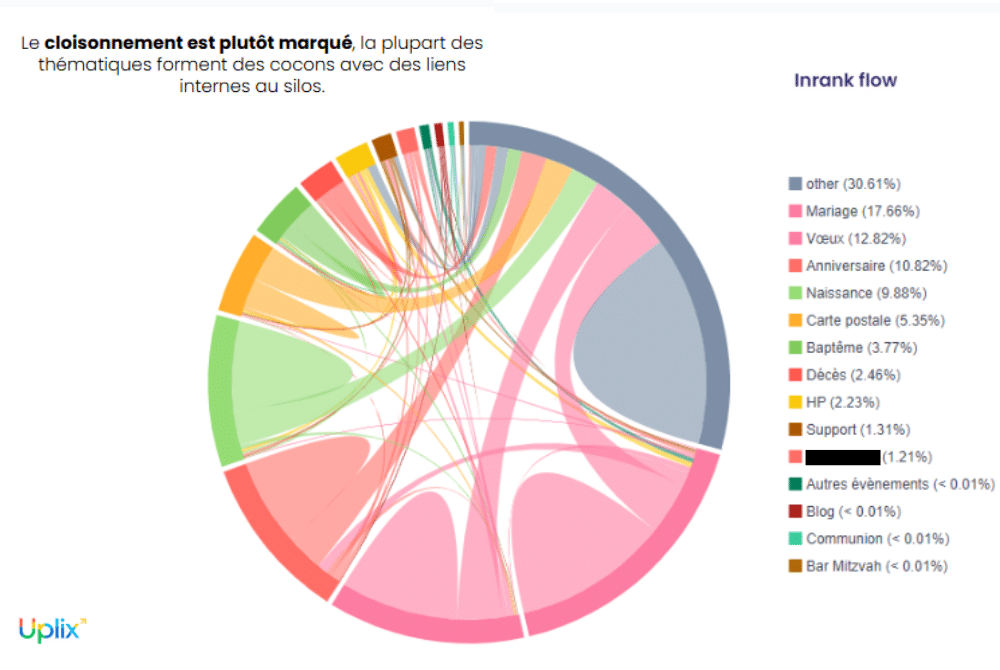
Ci-dessus : la répartition des liens dans le site par segments thématiques . Dans notre cas, cette analyse a permis d’affirmer l’efficacité de la stratégie d’obfuscation de liens en place sur le site.
Pour les autres, on renforcera le maillage interne et on envisagera une optimisation on-page si besoin.
Étape 6 : Traitement des pages orphelines
Les pages orphelines sont pour la plupart indexées, mais étant donné qu’elles n’ont pas de liens sur le site, elles ont une capacité de positionnement moindre. Parmi les pages orphelines, nous avons les pages sans potentiel (301, 404, peu pertinente, obsolète, etc) et les pages à potentiel qui convient de relinker sur le site.
Lors de l’analyse, plusieurs types de pages orphelines ont été identifiés :
- des pages retournant des codes 404 ou 3XX, issues, par exemple, d’anciens modèles de cartes supprimés ou d’URLs de filtres obsolètes, donc à nettoyer ou rediriger ;
- des pages générées par Google Shopping ou des campagnes email, contenant des paramètres de tracking non désindexés ;
- des variantes d’URLs canonicalisées ;
- des contenus à potentiel ignorés dans le maillage, comme certaines cartes virtuelles pour les fêtes ou invitations à thème saisonnier (Halloween, Fête des mères, rentrée des classes), pourtant stratégiques à l’approche des marronniers.
Les pages encore pertinentes ont donc été réintégrées dans le maillage interne, en créant de nouveaux liens contextuels depuis les pages les plus visitées ou depuis les hubs de catégories (ex. : « cartes de vœux », « événements familiaux »).
Les pages obsolètes, trop spécifiques ou redondantes, ont quant à elles été redirigées ou supprimées pour éviter toute cannibalisation ou dilution du budget crawl.
Étape 7 : Analyse des pics de crawl et planification des mises à jour éditoriales et techniques
Pour la dernière phase, nous avions besoin de connaître les moments où Googlebot (et les autres user-agent) visitent le plus intensément le site. Nous avons donc observé la cadence réelle d’exploration en ventilant les hits par jour et par tranche horaire, afin de faire ressortir des pics récurrents (par exemple, un fort passage de Googlebot entre 02 h 00 et 04 h 00 le jeudi).
Ainsi, nous avons visualisé l’évolution de la fréquence de crawl dans le temps, afin de repérer :
- des pics de crawl (souvent liés à des campagnes ou à la saisonnalité, parfois à des erreurs ou à des mises en ligne massives) ;
- des chutes soudaines de crawl sur certaines zones (souvent liées à une erreur de maillage ou une désindexation involontaire) ;
Or, grâce à Google Analytics, nous avions constaté que certaines catégories (cartes de vœux, idées cadeaux…) étaient davantage visitées à l’approche des marronniers (Noël, Fête des Mères). Par conséquent, en croisant ces données temporelles de trafic avec la fréquence de crawl par catégories de produits, nous avons été à même de calibrer un calendrier éditorial et technique chirurgical !
En effet, nous étions désormais capables de prédire les fenêtres de crawl favorables à la mise en ligne. Le principe est simple : faire coïncider les dates de publication et de mises à jour (avec une en-tête Last-Modified ou ETag pour attirer l’attention des bots) avec le pic de crawl à l’approche des périodes de fête ou de saisonnalité forte. Les URLs stratégiques se classent donc favorablement dans les SERPs au moment le plus propice à l’acquisition de prospects.
Dans le même temps, l’on reporte les opérations techniques lourdes (purges de cache, déploiements) hors pic de crawl, afin d’éviter les erreurs 5xx lorsque le bot passe le site au peigne fin.
Optimisation technique, éditoriale et algorithmique : le trio gagnant du projet et ses résultats
L’analyse croisée des logs, du crawl et des données de trafic a permis d’identifier plusieurs leviers d’optimisation concrets. En premier lieu, la définition de règles de gestion adaptées à la fonctionnalité des paramètres a permis de réduire le crawl inutile sur des pages dynamiques à faible valeur ajoutée (filtres, tris, sessions), allégeant ainsi la charge côté serveur et préservant le budget crawl.

Puis le renforcement du maillage interne a permis de remettre en lumière certaines pages stratégiques jusque-là sous-crawlées. En parallèle, les erreurs 404 ont été corrigées, et les chaînes de redirections traitées.
Enfin, en croisant les pics d’activité des bots avec les temps forts marketing, un calendrier de publication plus efficace a été mis en place : les mises en ligne éditoriales ou les mises à jour techniques sont désormais synchronisées avec les fenêtres de crawl les plus favorables, afin de maximiser l’indexation avant les pics de requêtes saisonniers.
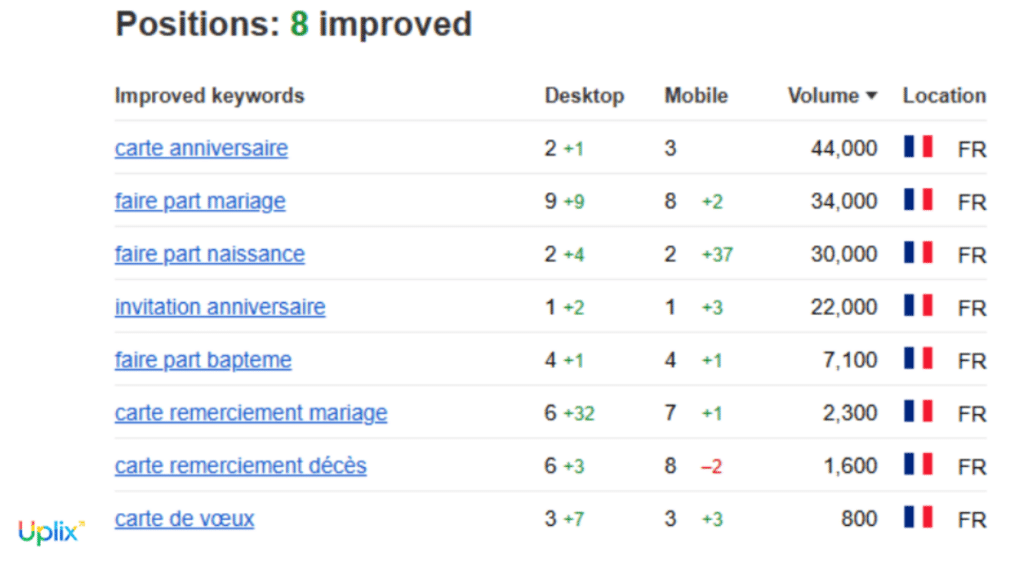
S’en est suivi une meilleure allocation du budget crawl, avec un Googlebot désormais orienté sur les pages à fort impact business. Bien que les effets sur le SEO ne puissent être isolés des autres optimisations menées en parallèle, l’intervention a clairement contribué à une amélioration globale de la couverture et de la visibilité organique du site.
Outils d’analyse de logs SEO : comment choisir et utiliser les meilleurs outils ?
L’analyse de logs SEO nécessite des outils capables de traiter de gros volumes de données tout en rendant l’information lisible et actionnable. Le choix de l’outil dépendra du niveau de technicité attendu, de l’infrastructure en place, mais aussi de la facilité d’intégration dans une stack SEO existante (Search Console, crawl, analytics, etc.).
Oncrawl : la solution d’analyse de logs pour les sites à forte volumétrie
Comme son nom l’indique un peu, on utilise souvent Oncrawl pour piloter du budget crawl. Sa capacité à ingérer massivement des fichiers logs dans les formats serveurs les plus courants en fait une solution adaptée aux sites complexes ou à fort trafic.
L’un de ses principaux atouts réside dans le croisement automatisé des données de logs avec les résultats du crawl interne et ceux de la Search Console, pour générer des analyses multi-sources très fines (ex. : pages crawlées mais non indexées, ou pages stratégiques jamais visitées par Googlebot).
Oncrawl propose également des tableaux de bord avancés et personnalisables, permettant aux experts de visualiser rapidement les pages orphelines, les anomalies dans le comportement des bots, ou les points de friction techniques. Le reporting automatisé facilite le suivi dans le temps et le partage avec les équipes métiers.
Pour les SEO techniques, les agences et les équipes internalisées souhaitant structurer leur stratégie de référencement de manière industrielle, Oncrawl est devenu une référence solide et évolutive.
Botify : pour structurer une stratégie SEO orientée business
Botify n’est pas qu’un outil d’analyse de logs, mais une plateforme conçue pour aider les grandes organisations à piloter leur stratégie SEO à l’échelle, en s’appuyant sur une vision consolidée des données crawl, logs, analytics et Search Console.
Contrairement à Oncrawl, qui est souvent utilisé pour monitorer finement le comportement des bots ou industrialiser la gestion du budget crawl, Botify permet une lecture plus globale et orientée KPI métier. On y croise systématiquement les signaux techniques avec les performances de trafic ou de revenus (sessions, conversions), ce qui en fait un bon candidat lorsqu’un client attend des recommandations priorisées par impact business, pas uniquement par volume ou fréquence de crawl.
Par ailleurs, l’outil se distingue par ses algorithmes de scoring et de prévision (notamment le Botify Intelligence), utiles pour répondre à des questions comme :
- quelles pages, si optimisées, ont le plus de chances de progresser en SEO ?
- quelles actions auront le plus d’effet à court terme sur l’indexation ou la performance organique ?
Côté prise en main, Botify demande souvent un temps de configuration plus long (notamment sur la partie tagging, intégration de KPIs custom, etc.) mais devient vite un atout quand l’objectif n’est pas seulement de faire un audit, mais bien d’outiller un pilotage SEO récurrent dans une logique de croissance durable.
Seolyzer : une solution accessible pour les sites modestes ou les audits ponctuels
Seolyzer constitue une alternative intéressante lorsque l’on ne dispose pas d’un budget ou d’un volume suffisant pour justifier une solution robuste comme Oncrawl ou Botify. L’outil s’adresse en priorité aux petits sites, aux structures légères, ou encore aux besoins ponctuels d’audit.
Il permet une analyse des logs en temps réel, avec une visualisation claire des pages les plus crawlées, des erreurs serveur, des pages orphelines ou encore des lenteurs de réponse. Surtout, il offre une segmentation dynamique selon les typologies d’URL, les périodes de crawl ou les codes de réponse HTTP — une aide précieuse pour identifier les zones de friction. Mais c’est surtout au moment de croiser les logs avec la Search Console ou un crawl interne qu’il révèle sa valeur, en rendant l’analyse exploitable et les recommandations fiables.
Enfin, son interface intuitive, ses API disponibles, et son hébergement conforme au RGPD en font un bon point d’entrée pour initier une démarche d’analyse de logs.
Critères de choix d’un outil d’analyse de logs
Le choix d’un outil ne dépend pas seulement de ses fonctionnalités, mais aussi de son adéquation avec les besoins du site ou de l’équipe. Plusieurs critères doivent être pris en compte :
- le volume de logs à traiter : plus le site génère de trafic, plus il faut un outil capable d’absorber de gros flux en continu.
- la fréquence d’analyse souhaitée : audit ponctuel ou monitoring quotidien ?
- les possibilités de croisement avec d’autres sources : outils de crawl, données Search Console, analytics… L’intégration multiplie la valeur des insights.
- la facilité de prise en main : selon que l’outil soit destiné à un profil technique, SEO ou mixte.
- le support et la documentation fournie : essentiels pour résoudre rapidement les blocages.
- le respect du RGPD et la sécurité des données : critère crucial, notamment si les logs contiennent des données sensibles ou des IP européennes.
Méthodologie pas à pas pour réussir son analyse de logs SEO
Réussir une analyse de logs repose sur une démarche structurée et rigoureuse. Voici une checklist des étapes clés à suivre, proche de notre cas d’étude :
| Étape | Action | Objectif |
| 1. Collecte des logs | Vérifier la complétude, le format et la période couverte | Disposer de données exploitables |
| 2. Configuration de l’outil | Paramétrage du crawl : user-agent, vitesse, mode js ou pas, etc… | S’assurer d’avoir une base de données la plus complète possible |
| 3. Segmentation des URLs | Catégoriser par structure d’url, type d’url, sémantique/thématique | Faciliter l’analyse ciblée |
| 4. Analyse des codes de réponse | Repérer codes 3XX, 4XX, 5XX, chaînes de redirection, spider trap | Corriger les erreurs techniques |
| 5. Identification du crawl | Observer le comportement des bots | Identifier les types de pages/ressources les plus et les moins crawlées |
| 6. Croisement avec les données de trafic | Comparer crawl et performances réelles | Évaluer la pertinence business |
| 7. Détection des pages orphelines | Identifier et traiter les pages non maillées | Optimiser le budget crawl et exploiter les pages à potentiel |
| 8. Analyse des pics de crawl | Étudier fréquence et moments de passage des bots | Planifier les mises à jour stratégiques |
| 9. Livraison des recommandations | Documenter et prioriser les actions | Fournir une roadmap claire et actionnable |
Audit de logs : les fondamentaux appliqués par Uplix
Quelle que soit la situation ou la démarche adoptée, l’on peut dégager au moins quatre constantes :
- toujours croiser les logs avec d’autres sources (crawl, analytics, Search Console) pour éviter les biais d’interprétation et fiabiliser les constats ;
- prendre en compte les contraintes techniques et organisationnelles du client (infrastructure, ressources, priorités business). L’on adapte ainsi les recommandations en proposant des solutions alternatives en cas de blocage technique ou de refus de changement (ex : compromis sur la pagination, solutions hybrides) ;
- ne pas se limiter aux gros sites : l’analyse de logs est pertinente pour tout site lors de migrations, refontes ou audits techniques ponctuels. L’on fera simplement varier l’outil selon l’envergure du projet : une solution simple comme SEOlyzer suffit pour un audit ponctuel, tandis qu’une solution plus robuste comme Oncrawl ou Botify sera recommandée pour un suivi continu ou des sites à forte volumétrie.
- documenter chaque étape et expliquer les recommandations pour faciliter la prise de décision, même si tous les correctifs ne sont pas applicables immédiatement.
L’analyse de logs, levier stratégique pour le SEO data-driven
L’analyse de logs est un levier stratégique permettant de mettre en lumière les angles morts du crawl, les contenus délaissés, les zones en surconsommation de crawl, et les signaux techniques défaillants. En 2025, dans un contexte de saturation concurrentielle sur Google, où chaque position gagnée peut avoir un impact direct sur le chiffre d’affaires, cette analyse approfondie, bien au-delà des audits classiques, donne accès à des leviers d’optimisation extrêmement fins pour gratter des places dans les SERPs.
Dans notre cas d’étude, cela s’est traduit par :
- une amélioration sur le top requêtes business grâce à la stratégie d’ouverture/fermeture de filtres ;
- la réduction du gaspillage de budget crawl lié à la prolifération de pages dynamiques ;
- la réintégration dans le maillage de pages à fort potentiel commercial ;
- la synchronisation des mises à jour de contenus avec les pics de crawl identifiés à l’approche des marronniers.
Quoi qu’il en soit, confier cette mission à un expert comme Uplix, c’est s’équiper des bons outils, croiser systématiquement les données et adopter une méthodologie rigoureuse pour transformer les logs en avantage concurrentiel durable, tout en évitant les pièges d’une mauvaise interprétation.



