

L’essentiel à retenir : l’erreur « Page indexée sans contenu » révèle un blocage de Googlebot par le serveur ou le CDN, et non un défaut de JavaScript. Identifiée par John Mueller, cette anomalie d’infrastructure exige une reconfiguration immédiate des accès. La persistance de ce statut technique conduit systématiquement à la perte totale de visibilité par désindexation.
L’alerte GSC page indexée sans contenu signale un dysfonctionnement technique où le moteur de recherche valide l’URL mais ne récupère aucune donnée exploitable. Contrairement aux hypothèses liées au JavaScript, ce guide démontre que l’origine du blocage se situe au niveau du serveur ou du CDN, comme le confirme John Mueller. L’application immédiate des correctifs de configuration présentés ici permet de rétablir l’accès pour Googlebot et de sécuriser le positionnement des pages menacées.
Décoder l’erreur « page indexée sans contenu » dans la GSC
Que signifie vraiment ce statut ?
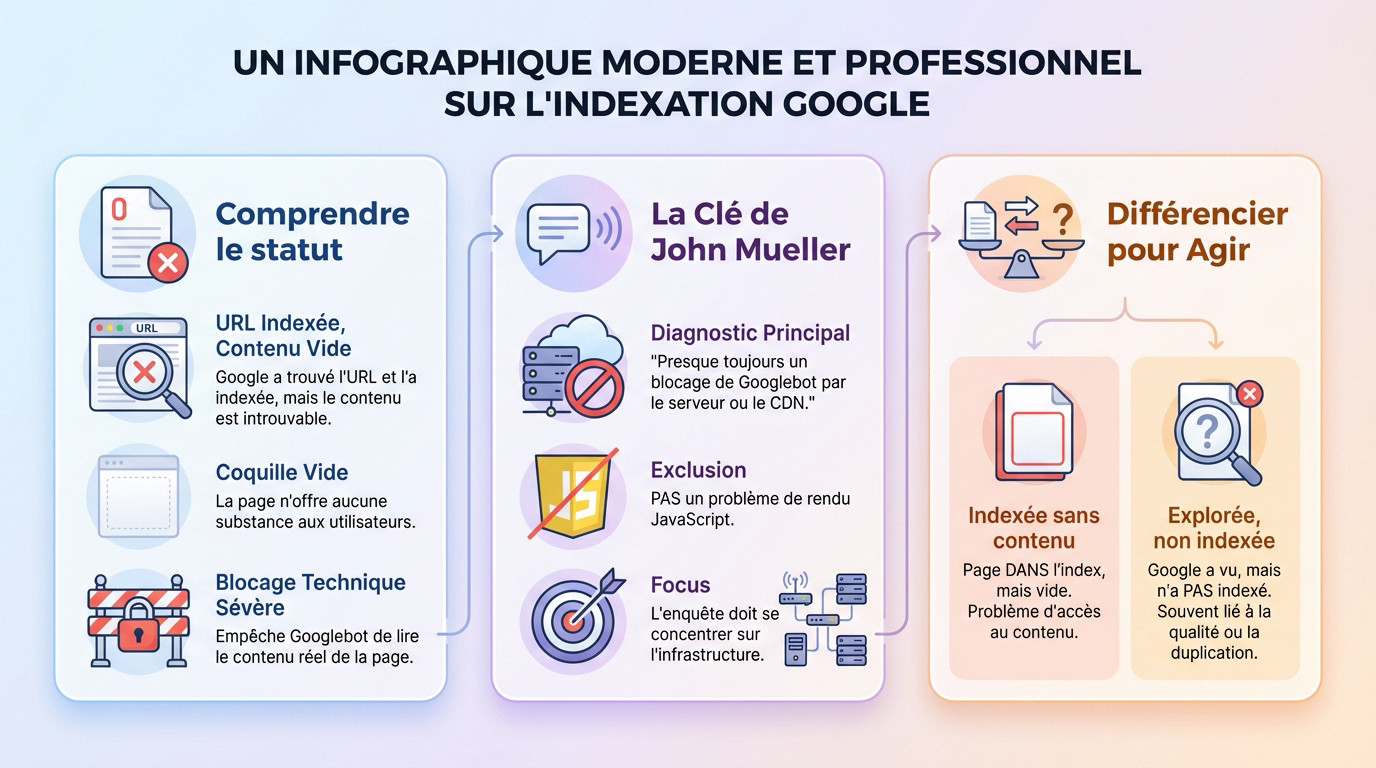
Ce statut de la Google Search Console (GSC) signale un problème technique. Google a bien trouvé l’URL et l’a ajoutée à son index. Mais le contenu récupéré est vide.
La page apparaît donc comme une coquille vide. Elle n’a aucune substance à présenter aux utilisateurs dans les résultats de recherche.
Ce n’est pas un simple avertissement. C’est le symptôme d’un blocage technique sévère qui empêche Googlebot de lire le contenu réel de la page, même si l’URL est techniquement indexée.
La clarification de John Mueller : une piste unique
John Mueller de Google a mis fin aux spéculations. La cause n’est pas à chercher côté client. Le problème se situe au niveau de l’infrastructure.
L’erreur ‘Page indexée sans contenu’ indique presque toujours un blocage de Googlebot par le serveur ou le CDN, et non un problème de rendu JavaScript.
Cette déclaration oriente le diagnostic technique. L’enquête doit se concentrer sur l’infrastructure serveur. Le rendu JavaScript est hors de cause dans ce cas précis.
Différencier pour mieux diagnostiquer
Il faut distinguer l’erreur « indexée sans contenu » du statut « explorée, actuellement non indexée ». Ce dernier signifie que Google a vu la page mais a décidé de ne pas l’indexer.
La décision de ne pas indexer est souvent liée à la qualité du contenu. Google écarte souvent les pages dupliquées ou sans valeur.
La différence fondamentale est claire. Dans notre cas, la page EST dans l’index, mais vide. C’est un problème d’accès au contenu, pas un jugement de valeur de la part de Google sur le contenu lui-même.
La véritable origine du problème : un blocage serveur ou cdn
Maintenant que le problème est défini, il faut identifier le coupable. L’enquête mène directement vers l’infrastructure qui héberge et distribue le site.
Le serveur : premier suspect dans la ligne de mire
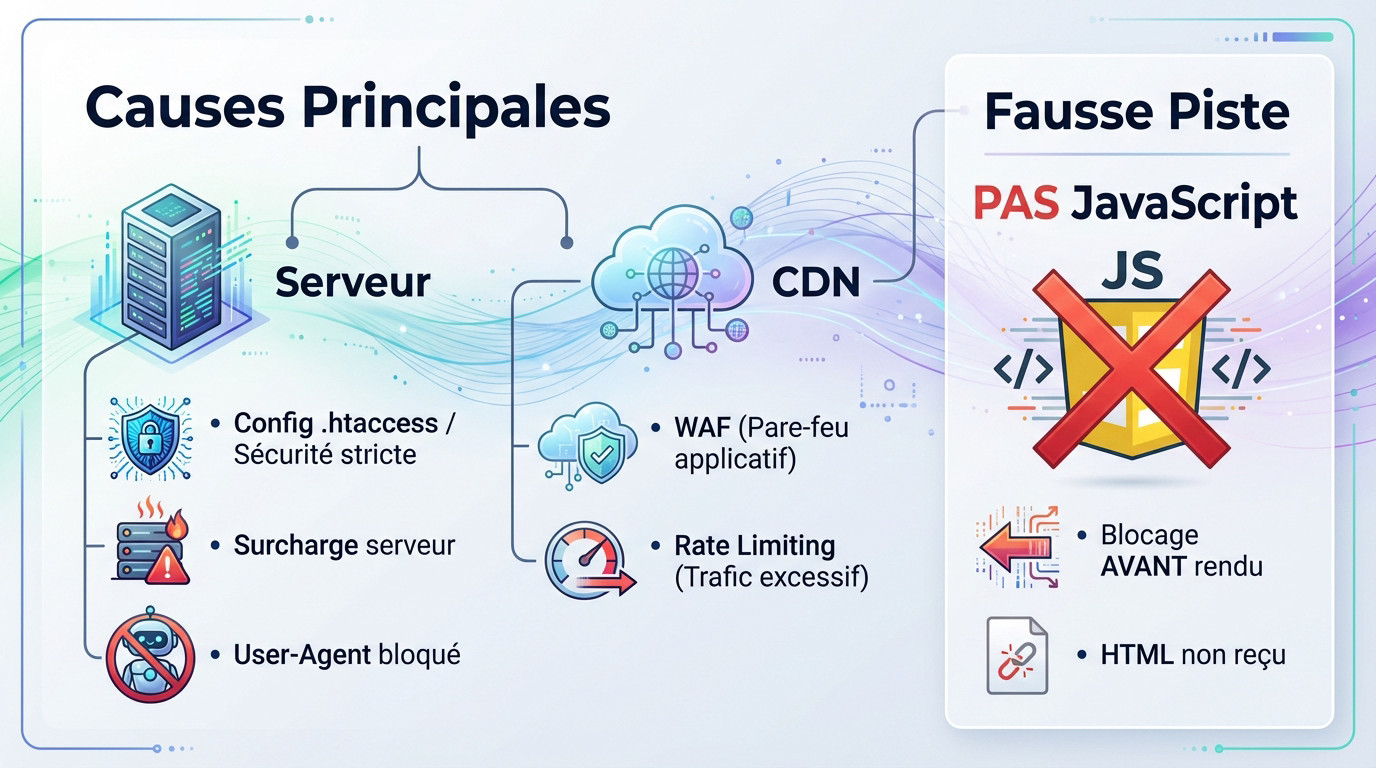
Le serveur web constitue la première source de blocage. Une configuration incorrecte du fichier .htaccess ou des règles de sécurité trop strictes refusent l’accès à Googlebot. Le robot trouve porte close.
Les surcharges serveur expliquent également ce phénomène. Si le serveur sature au moment du passage du robot, il renvoie une page vide. Le code de réponse indique alors une erreur technique.
Le serveur bloque parfois certains « user-agents » par précaution. Le bot de Google subit ce filtrage par erreur, ce qui empêche toute lecture des données.
Le rôle du cdn dans le blocage de googlebot
Le CDN (Content Delivery Network) optimise la performance mais provoque des coupures s’il est mal réglé. Il filtre le trafic avant qu’il n’atteigne le serveur d’origine. L’incident se produit souvent ici.
Les pare-feux applicatifs web (WAF) identifient parfois mal les visiteurs. Ils classent le trafic légitime de Googlebot comme une menace à tort. Le blocage devient immédiat et silencieux.
Les politiques de « rate limiting » entrent aussi en jeu. Si Googlebot explore le site trop agressivement, le CDN le bannit temporairement. Le crawl reste incomplet ou aboutit à une page blanche.
Écarter la fausse piste du javascript
Il faut écarter la piste du JavaScript. John Mueller confirme que l’erreur GSC page indexée sans contenu ne provient pas d’un défaut de rendu.
Un problème JS implique que Google accède au squelette HTML mais échoue à exécuter le script. Le contenu reste masqué, mais le code est bien reçu.
Ici, Google ne reçoit même pas le code source initial. Le blocage survient radicalement en amont du processus de rendu. La page reste invisible.
Diagnostiquer la source exacte du blocage
Analyser les logs de votre serveur
Les logs serveur sont une mine d’or pour l’analyse technique. Ils enregistrent chaque requête reçue. L’expert doit y isoler les lignes correspondant au user-agent de Googlebot pour confirmer son passage.
Il faut surveiller les requêtes du bot recevant des codes de réponse anormaux, comme des erreurs 5xx. Ces anomalies signalent un rejet direct par le serveur.
Une absence totale de logs pour les URL ciblées révèle souvent un blocage en amont. Cela indique généralement une restriction active au niveau du CDN.
Utiliser les outils de la google search console
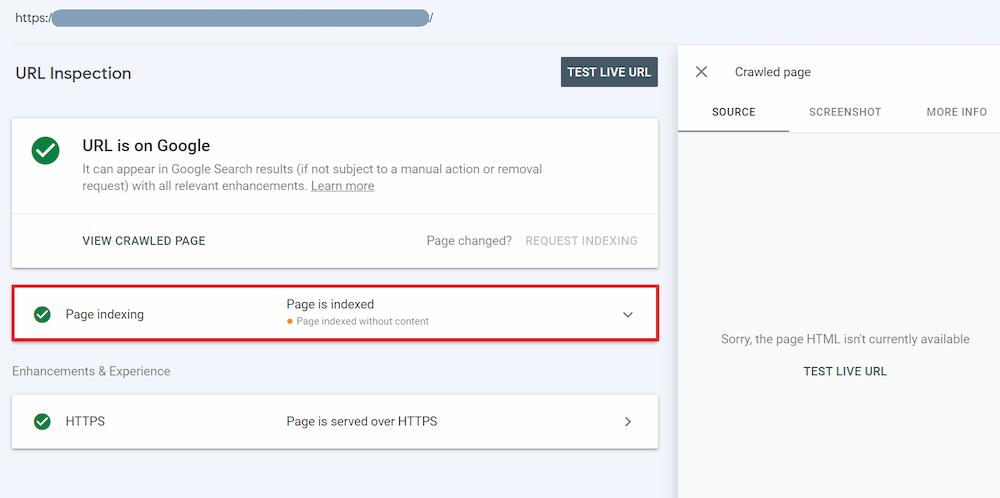
L’Outil d’Inspection de l’URL est le premier réflexe face à l’erreur `GSC page indexée sans contenu`. Il montre précisément comment le moteur perçoit une page spécifique.
La fonction « Tester l’URL en direct » vérifie si Googlebot accède à la ressource. Une erreur affichée ici constitue un signal clair de blocage technique.
L’exploration de cet outil indispensable qu’est la Google Search Console fournit des indices précieux. Ces données clarifient l’état du crawl et orientent les correctifs.
Vérifier les performances et les codes de réponse
Un temps de réponse serveur excessif provoque souvent un « timeout » du robot. Googlebot abandonne alors la requête avant d’avoir reçu le contenu.
Le TTFB (Time To First Byte) est une métrique critique à surveiller dans la GSC. Une latence élevée nuit gravement à l’exploration.
Une vérification systématique des éléments techniques s’impose :
- Codes de réponse HTTP : rechercher les 403 Forbidden ou 5xx.
- TTFB : un temps trop long est un drapeau rouge.
- Configuration du firewall : règles de blocage par IP.
- Paramètres de sécurité du CDN : règles WAF trop agressives.
Actions correctives immédiates pour résoudre le conflit
Le diagnostic est posé. Il est temps de passer au traitement. Voici les actions concrètes pour rouvrir la porte à Googlebot et assurer une exploration saine.
Configurer correctement le serveur et le cdn
La première étape consiste à rectifier les configurations pour corriger l’erreur GSC page indexée sans contenu. Il s’avère impératif de garantir que les adresses IP de Googlebot figurent sur la liste blanche. Cette action rétablit le dialogue.
Google met à disposition la liste officielle de ses plages d’adresses IP. L’autorisation explicite de ces données reste une procédure technique élémentaire.
- Mettre en liste blanche les IP et le user-agent de Googlebot.
- Ajuster les règles du WAF pour être moins sensible au crawl de Google.
- Vérifier les fichiers de configuration serveur (ex: .htaccess) pour toute règle de blocage involontaire.
L’importance d’un audit technique seo
Un audit technique SEO approfondi devient souvent indispensable face à ce type d’erreur critique. Ce blocage ne représente parfois que la partie visible de l’iceberg. L’analyse doit contrôler la santé globale de l’infrastructure web. Une vision d’ensemble s’impose.
Cette inspection minutieuse englobe l’examen des codes de réponse de chaque URL. Elle évalue aussi la performance globale du site. La lisibilité du code source est scrutée.
L’objectif final vise à certifier l’absence de frictions techniques. Rien ne doit entraver le crawl.
Améliorer le maillage interne pour guider googlebot
Même après la levée du blocage, un maillage interne cohérent demeure fondamental. Cette structure logique aide Googlebot à redécouvrir les pages. Il interprète ainsi correctement l’architecture globale. Le robot comprend mieux la hiérarchie.
Les pages bénéficiant de liens contextuels pertinents subissent une exploration plus fréquente. Cette mécanique accélère considérablement la prise en compte. Les corrections techniques sont vite validées.
C’est une solution pour l’indexation de vos pages qui dépasse la simple résolution du bug. Elle traite le problème technique initial. Le SEO se renforce durablement.
Prévenir la désindexation et accélérer la récupération
Le risque réel de désindexation et son impact
Une page marquée comme GSC page indexée sans contenu ne reste pas indéfiniment dans l’index. Google fait le ménage rapidement si le problème persiste. L’urgence est réelle pour conserver ses positions acquises.
Si Google constate de manière répétée qu’une page est vide, il finira par la désindexer, considérant qu’elle n’apporte aucune valeur à l’utilisateur.
La désindexation signifie une perte totale de visibilité et de trafic organique pour les pages concernées. Le site disparaît littéralement des résultats de recherche. Il faut agir vite pour éviter ce scénario.
Demander une nouvelle indexation après correction
Une fois les blocages serveur ou CDN levés, il ne faut pas attendre passivement le prochain passage du bot. Le temps joue contre le référencement du site. Il faut informer Google que le problème technique est désormais résolu.
Retournez dans l’Outil d’Inspection de l’URL de la GSC immédiatement. Utilisez la fonction « Demander une indexation » pour toutes les URL corrigées afin de forcer une nouvelle visite du robot.
Cette action place la page dans une file d’attente d’exploration prioritaire. Cela accélère la récupération des positions et la prise en compte du contenu réel.
L’audit sémantique pour renforcer la pertinence
Profitez de cette maintenance technique pour aller plus loin dans l’optimisation globale. Un audit sémantique garantit que le contenu, une fois accessible, est jugé pertinent et qualitatif par Google.
Il faut s’assurer que le contenu est unique sur le site et évite la duplication. Il doit répondre à une intention de recherche claire et être correctement structuré pour les algorithmes.
- Vérification du caractère unique du contenu face aux doublons internes.
- Optimisation des balises sémantiques (titres, Hn) pour la hiérarchie.
- Alignement du contenu avec l’intention de recherche de l’internaute.
L’erreur « Page indexée sans contenu » révèle un blocage technique critique. John Mueller confirme l’origine côté serveur ou CDN, écartant la piste JavaScript. Une reconfiguration immédiate des accès pour Googlebot s’impose pour rétablir le crawl. L’inaction entraîne un risque élevé de désindexation définitive, nuisant gravement à la visibilité organique.
FAQ
Quelles sont les causes d’une page indexée sans contenu par Google ?
L’erreur signalée par la Search Console provient majoritairement d’un blocage du Googlebot au niveau du serveur ou du CDN. John Mueller précise que les problèmes de rendu JavaScript ne sont pas responsables de ce statut spécifique.
Le robot d’exploration accède à l’URL mais se heurte à une barrière de sécurité ou une mauvaise configuration. Le contenu textuel n’est donc pas récupéré, laissant une coquille vide dans l’index du moteur de recherche.
Comment résoudre le blocage technique affectant l’indexation ?
La priorité est de revoir la configuration du pare-feu applicatif (WAF) et du serveur web. Il est impératif d’autoriser explicitement les plages d’adresses IP officielles utilisées par les robots de Google via une liste blanche.
Une vérification des fichiers de configuration, tels que le .htaccess, s’impose pour supprimer toute règle bloquante involontaire. L’objectif est de garantir que le serveur renvoie un code HTTP 200 accompagné du code HTML complet.
Comment vérifier la bonne lecture de la page par le moteur ?
L’utilisation de l’outil d’inspection d’URL dans la Google Search Console permet de simuler le passage du robot en temps réel. Cette fonctionnalité indique immédiatement si le contenu est accessible ou si l’accès est refusé.
L’analyse des logs serveur offre une confirmation technique supplémentaire indispensable. Elle permet de repérer les tentatives d’accès du user-agent Googlebot ayant échoué avec des erreurs de type 403 ou 5xx.



