

L’essentiel à retenir : Google déploie Google-Agent, un nouveau robot révolutionnaire piloté par l’action humaine en temps réel. Ce « user-triggered fetcher », lié au Project Mariner, peut naviguer et remplir des formulaires à la place de l’utilisateur. C’est crucial pour votre SEO, car l’IA ne se contente plus de lire, elle agit. Un fichier JSON officiel permet d’identifier ces requêtes de 15 Mo maximum. Pour en discuter directement: Contactez- nous!
Marre de voir des robots piller vos données sans jamais savoir qui commande vraiment derrière l’écran ? Le nouveau google fetcher ia change la donne en s’activant uniquement sur ordre d’un humain pour naviguer ou remplir des formulaires à sa place. Découvrez comment identifier ce visiteur inédit dans vos logs et ajuster vos réglages pour dompter cette intelligence agissante sans sacrifier votre précieux trafic.
Google-Agent : le visiteur surprise qui change tout pour l’IA
Après des années de crawl passif, Google change de braquet avec des agents qui agissent au nom de l’utilisateur.
Qu’est-ce qu’un fetcher déclenché par l’utilisateur ?
Un « user-triggered fetcher » est un robot spécial. Contrairement au Googlebot classique qui indexe le web seul, celui-ci s’active uniquement via une requête humaine. C’est une interaction directe et en temps réel.
Ici, l’action humaine est le véritable moteur. Vous demandez une synthèse et le fetcher s’exécute immédiatement pour vous.
Le rôle de Project Mariner dans cette navigation automatisée
Project Mariner représente une évolution majeure : un agent capable de piloter un navigateur. Il ne lit plus seulement le contenu. Il interagit désormais avec les éléments d’une page web complexe.
Ses capacités incluent le remplissage de formulaires. L’agent peut simuler des clics ou des saisies pour extraire des informations précises.
Project Mariner marque le passage de l’indexation passive à une assistance proactive et dynamique sur le web.
Pourquoi ce déploiement progressif mérite votre attention
Le calendrier de déploiement s’étale sur plusieurs semaines. Ce n’est pas un simple test. C’est une transformation profonde des infrastructures mondiales de récupération de données.
Surveiller vos logs devient donc impératif. Ces nouveaux agents vont impacter la charge de vos serveurs et vos statistiques de visites.
Rester vigilant est crucial. Les outils comme le Google AI Mode utilisent déjà ces technologies.
Comment débusquer Google-Agent dans vos logs serveurs
Pour ne pas confondre ces nouveaux visiteurs avec des bots malveillants, il faut savoir lire entre les lignes de vos logs.
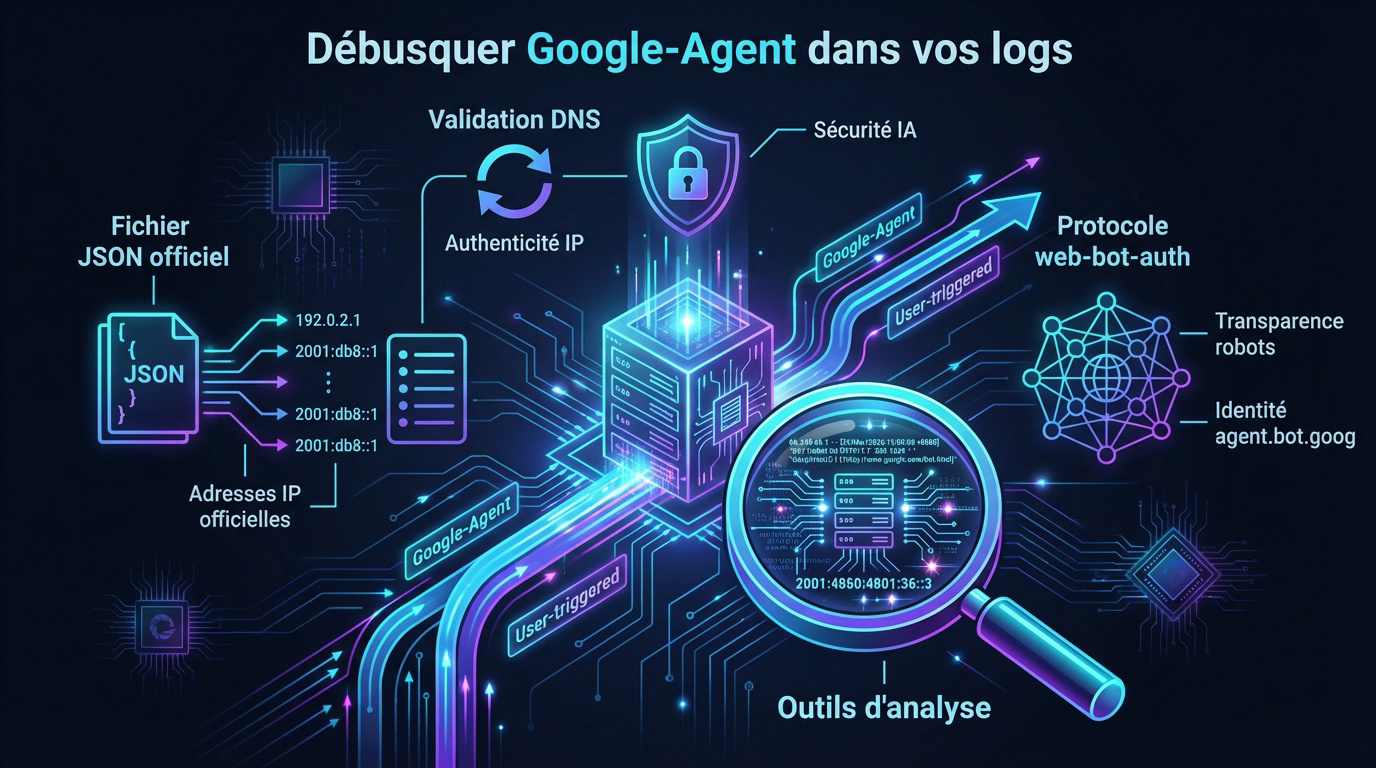
Identifier les plages IP et le fichier JSON officiel
Foncez consulter le fichier user-triggered-agents.json fourni par Google. Ce document liste toutes les adresses IP officielles. C’est la base pour filtrer proprement vos accès serveurs.
Isolez ces requêtes facilement. Utilisez des outils d’analyse de logs pour créer des segments spécifiques.
- Nom de l’agent : Google-Agent
- Fichier source : JSON officiel
- Type : User-triggered
Utiliser le DNS inversé pour valider l’authenticité
Utilisez la méthode du reverse DNS sans tarder. Elle permet de vérifier que l’IP appartient bien à Google. C’est la seule parade efficace contre l’usurpation d’identité par des bots tiers.
Vérifiez les masques DNS. Ils confirment l’origine légitime de la requête. Cela sécurise votre infrastructure contre les faux crawlers.
Cette étape est indispensable. Elle garantit l’intégrité de vos données d’audience.
L’expérimentation du protocole web-bot-auth
Découvrez l’identité agent.bot.goog dès maintenant. Google teste ce nouveau standard pour simplifier la transparence. L’objectif est de rendre l’authentification des robots plus fluide et universelle pour tous les webmasters. C’est un pas vers un web plus clair.
Cette norme émergente change tout. Elle vise à réduire la friction entre les serveurs et les agents d’IA.
Faut-il laisser l’IA de Google lire tout votre contenu ?
Une fois ces agents identifiés dans vos logs, une question brûlante se pose : faut-il leur ouvrir grand la porte ou restreindre leur accès ? C’est un arbitrage délicat entre protection de la data et visibilité future.
Gérer les accès sélectifs via le fichier robots.txt
Distinguez bien Google-Agent des robots d’entraînement comme GPTBot. Le premier agit pour un humain, le second pour nourrir un modèle. Vous pouvez bloquer l’un sans pénaliser l’autre. C’est une gestion fine de vos ressources.
Autorisez ces accès sans impacter votre indexation SEO globale. Utilisez des directives spécifiques dans votre fichier robots.txt. Cela permet de rester visible dans Google Search tout en contrôlant l’IA. Vous gardez ainsi la main sur votre stratégie.
Le choix entre recherches par IA et Google Search classique dépendra de votre tolérance au crawl. Gérez vos priorités avec soin.
L’impact sur la visibilité et la synthèse des données
Évaluez le gain de visibilité réelle. Les outils de lecture assistée citent souvent leurs sources. Cela peut générer un trafic qualifié, même si l’utilisateur ne parcourt pas l’intégralité de votre article. C’est une nouvelle forme d’exposition.
Un compromis est pourtant nécessaire. La synthèse par l’IA peut réduire le nombre de clics directs vers votre site. Pourtant, être absent de ces résumés pourrait vous rendre totalement invisible à l’avenir. Le risque d’effacement est bien réel.
Le défi de demain sera de nourrir l’IA sans sacrifier le trafic vers nos propres plateformes numériques.
C’est un équilibre fragile. Chaque éditeur doit définir sa propre politique d’accès dès maintenant.
3 réglages malins pour aider les fetchers à vous lire
Si vous choisissez de collaborer, voici comment optimiser techniquement vos pages pour ces nouveaux agents.
Respecter les limites de taille et les encodages supportés
Gardez en tête la limite de 15 Mo par fichier. Au-delà, Google-Agent risque de tronquer votre contenu. Allégez vos pages pour garantir une lecture complète par l’IA.
Utilisez impérativement Brotli ou Gzip pour vos compressions. Ces formats boostent la récupération des données. Une réponse serveur rapide améliore nettement l’expérience de votre utilisateur final.
Voici les points clés à surveiller pour vos fichiers :
- Limite de taille : 15 Mo
- Compressions : Brotli / Gzip
- Encodage : UTF-8 recommandé
Exploiter la mise en cache HTTP pour vos ressources
Misez sur les en-têtes ETag et Last-Modified sans hésiter. Ces balises signalent au fetcher si votre contenu a bougé depuis son dernier passage. Vous évitez ainsi de transférer des fichiers strictement identiques. C’est un gain de performance massif pour votre infrastructure.
Réduire la charge serveur devient alors un jeu d’enfant. Une gestion fine du cache stoppe les requêtes redondantes. Votre machine reste disponible pour les humains tout en servant efficacement l’IA.
Pour aller plus loin dans l’optimisation ou Pour en discuter directement : Contactez-nous !. Nos experts vous aideront à configurer vos serveurs.
L’arrivée du Google-Agent et du protocole web-bot-auth transforme radicalement l’interaction entre l’IA et vos serveurs. Identifiez vite ce nouveau google fetcher ia dans vos logs pour anticiper l’impact du Project Mariner sur votre trafic. Préparez dès maintenant vos infrastructures techniques pour briller dans cette nouvelle ère agentique !



