

Qu’est-ce que le NLP ?
Quand l’intelligence artificielle entre en synergie avec le langage humain, l’on obtient le Natural Language Processing (NLP).
Avec des outils de traitement de langage naturel comme Google NL API, l’on devine, à l’ère de l’hyper communication, que chaque avancée peut avoir un impact de grande envergure sur notre quotidien.
En effet, le NLP désigne la compréhension du langage humain par les machines. Imaginez un gros volume d’informations écrites.
La machine ne recueille que les éléments qui vous intéressent : compétences essentielles dans une pile de CV, points négatifs dans une section commentaires, vices au cœur d’un contrat, etc. On s’épargne ainsi de longues heures de lecture inutile.
Encore plus étonnant, l’organisme OpenAI a sorti GPT-2, un logiciel capable de rédiger des articles ! Voyons plus avant comment les NLP sont en mesure d’optimiser votre temps de travail ; Google NL API nous servira notamment d’illustration.
Le NLP : fruit des recherches en Machine Learning, en Deep Learning et en linguistique
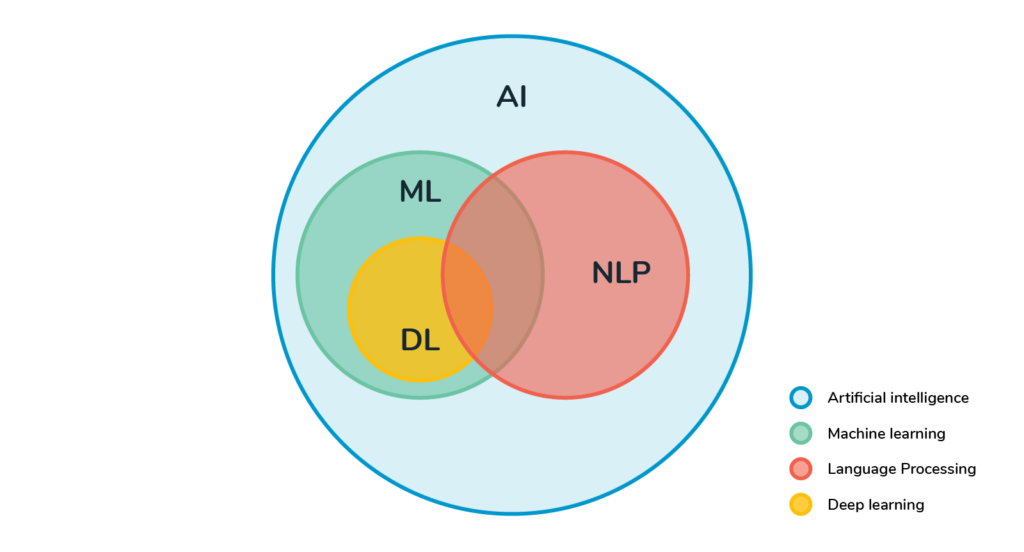
Le NLP ou, en français, Traitement Automatique du Langage Naturel (TALN), c’est ni plus ni moins que la faculté d’un ordinateur à interpréter du langage naturel humain, et de réagir conformément à ce que lui suggère chaque message. Un grand pas en avant dans la fluidification des interactions entre l’homme et la machine !
En apprenant à traiter l’information à la manière d’un cerveau humain, les intelligences artificielles peuvent accomplir des tâches rébarbatives à une vitesse extraordinaire.
En effet, convertir des textes issus de courriels, d’enquêtes, de réseaux sociaux, forums,etc. en données exploitables prend beaucoup de temps à un humain.
Mais pour parvenir à établir une communication en langage naturel avec les modules informatiques, il a fallu y intégrer les subtiles règles du langage humain, en les associant à une capacité d’apprentissage autonome. Mais où en sommes-nous à l’heure actuelle ?
Ce que sait faire un NLP ?
L’intelligence artificielle intègre un algorithme qui utilise une base de données. À partir de récurrences, de patterns, de corrélations, elle devient peu à peu capable de décomposer le langage humain afin d’y dégager des éléments de sens.
Les progrès dans le Deep Learning permettent un tel apprentissage automatique, lequel est capital dans l’assimilation d’une langue.
Ensuite, pour convertir un texte en données, elle apprend à éliminer le superflu en fonction de la recherche (des liens URL, des émoticônes, chiffres, symboles, etc.). En somme, c’est toute la partie linguistique qu’on exploite ici.
Un peu à la manière de notre cerveau, la machine catégorise les éléments du discours. Elle segmente en séparant des mots et des groupes de mots pour leur attribuer une fonction, notamment à travers l’étude de leur morphologie.
En d’autres termes, elle sait reconnaître un groupe nominal sujet, un verbe conjugué, un complément, etc. Elle distingue le genre et le nombre, la personne (1re du sing., 2e et ainsi de suite…), la racine et la terminaison.
L’analyse grammaticale d’une phrase par une intelligence artificielle est appelée “parsing”.
Toutefois, certaines règles comportant des exceptions échappent encore à la sagacité des IA : le “s” du pluriel, pas systématique et assez anecdotique morphologiquement, est parfois mal assimilé.
L’analyse sémantique
Cette approche est beaucoup moins structurelle, donc beaucoup plus délicate pour un cerveau non humain. Il s’agit de saisir des éléments contextuels, d’établir des comparaisons avec d’autres textes, comprendre quels sentiments sont véhiculés, sans parler du contenu substantiel, qui peut toujours être parasité par des effets de langue.
En effet, comment faire reconnaître à une machine une antiphrase, un trait sarcastique, une métaphore ou une question rhétorique ?
Mais si un texte ne comporte pas trop de nuances, il résiste bien moins au traitement informatique. Cela étant, dans l’ensemble, l’analyse sémantique demeure partielle.
Cela n’empêche pas les NLP d’extraire en un temps record des données importantes à rentrer dans un tableau statistique pour benchmarker un domaine d’activité ou auditer une entreprise.
Transformer un texte informel en données numériques
Avec les NLP, il existe des tâches plus ou moins avancées. L’enjeu est toujours de trier des quantités astronomiques d’informations non structurées, et d’en tirer profit rapidement.
On trouve ainsi des fonctionnalités simples, telles que Term-Frequency, ou “la fréquence des termes” : il s’agit de faire relever à votre ordinateur un nombre d’occurrences d’un mot ou d’un groupe de mots (aussi appelés “tokens”, dans le jargon).
Cette méthode fondée sur une règle simple permet de détecter les spams en identifiant des tokens tels que “promotion exceptionnelle”, “concours”, ou “offre à durée limitée”, etc.
Le “Term Frequency-Inverse Document Frequency” va plus loin, puisqu’il permet de comparer en proportion le nombre d’occurrences d’un token dans les textes d’un même corpus.
Plus avancé encore, le “Word Embedding” tient compte du contexte dans lequel sont employés les mots. Cela permet d’un peu mieux cerner les axes sémantiques d’un contenu.
Champ d’application des NLP
Vous commencez à vous en douter : il y en a des dizaines ! En effet, un tel assistant dans le traitement de l’information sert à quiconque utilise du langage humain, autrement dit tout le monde ! Le simple fait que votre boîte mail ou moteur de recherche parvienne à anticiper un mot ou une fin de phrase que vous vous apprêtez à écrire, voire à vous suggérer des réponses, relève des NLP.
Quelques usages dans le cadre privé
Drôle d’époque où nous utilisons et bénéficions de technologies avant même d’en connaître le nom ! Voici donc des cas que vous avez probablement déjà rencontrés :
- logiciels et applications de traduction : Google Translate ou DeepL font des progrès magistraux pour traduire instantanément des discours de longueurs variables, tant que leur sens reste univoque ;
- assistants personnels : Siri, Google Home ou encore Alexa réagissent à des demandes formulées assez naturellement, même si cela reste loin d’être fluide ;
- les chatbots (comme celui de la SNCF) ou les Interactive Voice Responses (IVR) parviennent à traiter certaines requêtes automatiquement, et ce n’est qu’un début ;
- les traitements de texte comme Microsoft Word ou les correcteurs tels qu’Antidote sont capables de pointer toutes vos erreurs et même de vous indiquer la règle grammaticale qui lui correspond. Cela étant, il existe encore plein de situations où l’ordinateur est perdu…
Utilisation dans le domaine professionnel
Dans ce cadre, l’on exploite sciemment les possibilités du Traitement Automatique du Langage Naturel à des fins commerciales :
- classification d’éléments du discours : on l’a vu, les NLP peuvent décomposer un texte afin de rentrer ses éléments dans les catégories préalablement définies. Une bonne manière de mettre de l’ordre dans un ensemble de plusieurs centaines, voire milliers de textes !
- reconnaissance de caractères : on peut demander à une machine de faire ressortir d’un texte les informations dont on a besoin uniquement, sans avoir à parcourir soi-même la totalité du document. Factures, contrats, reçus, chèques, etc… À un certain degré de subtilité, cela pourrait profiter aux recherches bibliographiques d’un bon nombre de thésards !
- résumé automatique : qui n’a jamais rêvé de lire la version synthétique, mais rigoureusement exacte d’un discours philosophique du XIIIe ? Bon, à l’heure actuelle, on est plutôt sur des comptes-rendus, mais c’est bien aussi !
- l’analyse des sentiments sert à évaluer le niveau de satisfaction des clients dans une section commentaires. Les sondages seront-ils bientôt obsolètes ? ;
- marketing : en s’appuyant sur le comportement des internautes, leurs recherches et leurs interactions, Google propose des publicités adéquates, c’est-à-dire de nature à potentiellement satisfaire un besoin client ;
- SEO avec l’exemple de l’algorithme BERT : depuis fin 2019, le moteur de recherche de Google a cessé de traiter les requêtes mot par mot. Il est devenu capable de trouver les liens existant entre les termes, et de tenir compte du contexte de la recherche. De quoi chambouler le référencement des sites internet !
Axes d’amélioration pour les NLP
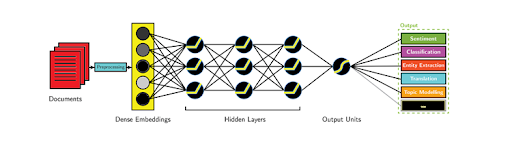
Actuellement, la balle est plutôt dans le camp des chercheurs en Machine Learning et surtout Deep Learning (voir ci dessous). C’est cette technologie qui permet aux ordinateurs de dépasser la simple reconnaissance et classification des éléments de langage, pour arriver à une interprétation de sens plus proche de celle d’un cerveau humain.
La gageure est d’intégrer des modèles d’apprentissage performants, qui nécessitent une phase de prétraitement des données moins conséquente. Aujourd’hui, l’on s’intéresse à plusieurs phénomènes de langue plutôt complexes :
- synonymie : il faut assimiler la notion de polysémie des mots (poly = plusieurs ; sémie = sens) et choisir le bon sens en fonction du contexte (“planté” est-il synonyme de “cultivé” ou de “immobile” ?)
- coréférence : lorsque l’on parle du “Soleil”, on peut utiliser des périphrases comme “l’étoile au cœur du système solaire” ou des noms dérivés : “l’astre solaire”, ou la “naine jaune”. Cette simple aptitude à savoir associer toutes ces expressions à un seul objet signifié est primordiale pour les tâches de haut niveau des NLP ;
- ambiguïté : il ne faut pas confondre “les enfants qui ont bien travaillé à l’école iront à la boulangerie-pâtisserie” et “les enfants, qui ont bien travaillé à l’école, iront à la boulangerie-pâtisserie”. Dans le premier cas, on discrimine deux catégories d’enfant, les travailleurs et les autres. Dans le second, on qualifie l’ensemble des enfants comme des travailleurs. Ces problèmes de langue pullulent et sont un véritable problème pour les machines ;
- genre, registre et figures de style : il existe des différences notables entre un discours ironique (second degré) et un discours laudatif (élogieux), ou entre des expressions familières et soutenues. D’autre part, il est impératif de bien saisir des modulations du discours, comme les euphémismes (atténuation) ou les hyperboles (exagérations), sans quoi l’on peut vite basculer dans des contresens !
Google NL API : pourquoi et comment s’en servir ?
Google Natural Language API est un outil Google Cloud qui exploite un NLP de niveau relativement primitif, mais qui peut déjà dégager des données sur des corpus très volumineux. Malgré une certaine rigidité et une très légère marge d’erreur, Google NL API parvient à performer sur des contenus assez univoques.
Il est donc possible d’en extraire des statistiques fiables. Google NL API propose ainsi cinq services différents, dont le coût varie en fonction du volume de la requête (de gratuit à plusieurs centaines de dollars). Ce sont des outils rapides, qui ne requièrent pas de connaissances techniques, mais qui conviendront à un usage simple sur des quantités moyennes, au risque de revenir cher.
Analyse syntaxique
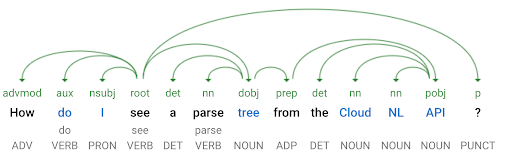
Facile à coder, c’est un travail de grammairien pur et dur. En effet, celui-ci consiste à ventiler chaque mot en détaillant sa nature et sa fonction grammaticale. Il précisera le genre et le nombre des noms, le temps, la personne et la voix (active/passive) des verbes, il distinguera les conjonctions, déterminants et adverbes, etc.
Même la ponctuation est prise en compte ! L’analyse plus poussée consiste en des “arbres de dépendance”, qui font penser aux “stemmas”. Ils mettent en relief les liens grammaticaux des mots qui composent une phrase. Les flèches matérialisent le changement morphologique d’un mot par rapport à la présence d’un autre mot.
Nota bene : après un certain nombre de requêtes, ce service devient payant. Il sert avant tout à créer des fonctionnalités pour des modèles de Machine Learning.
Analyse des sentiments
Ce service peut être utilisé indépendamment d’autres fonctionnalités. Il fait ressortir d’un document l’impression émotionnelle générale qui s’en dégage. L’évaluation reste relativement binaire, qui se mesure en magnitude. Elle part de 0 (neutralité) et oscille entre 1 (positif) et – 1 (négatif). Ainsi, le NLP est capable de prendre un grand nombre d’avis postés sur un sujet, et d’établir un bilan exact à peu de choses près des sentiments émis par les internautes.
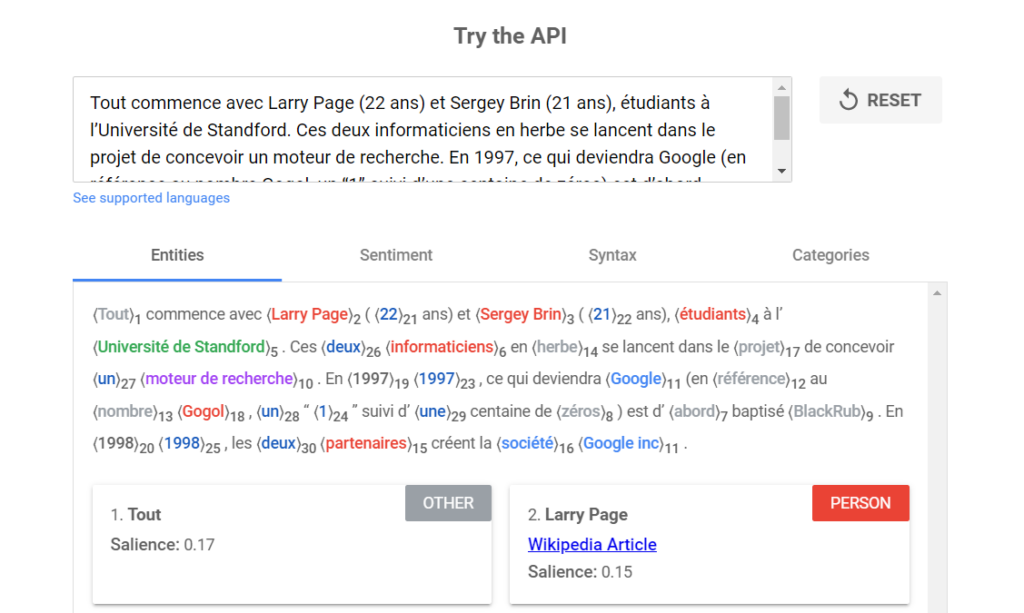
Analyse des entités
Cette fonctionnalité est simple, mais peut s’avérer très efficace pour des recherches spécifiques. L’analyse des entités consiste à détecter dans un texte des tokens remarquables, souvent sous forme de chiffres et de noms propres. En effet, la machine saura reconnaître une organisation, une date, un lieu, un prix, une adresse, un personnage célèbre, une œuvre d’art, etc.
Analyse des sentiments vis-à-vis d’entités
Il s’agit d’une combinaison entre les deux tâches précédentes, à savoir quel type de sentiment est associé à une entité identifiée dans un texte. Dans ce cas, l’analyse émotionnelle se cantonne à tous les sentiments dépendants de l’entité en question. Parfait pour les démarches UX !
Classification de texte plug-and-play
Cette dernière fonctionnalité sert à ranger dans des catégories et sous-catégories prédéfinies un ensemble de documents divers. Articles, publicité, courriels, etc. pourront ainsi être classés facilement.
Google AutoML Natural Language

Il s’agit de la version avancée du Google Natural Language API. Plus flexible, mais également plus compliqué à mettre en place, il fait également partie des services Google Cloud. Celui-ci vous permet de créer vous-même un modèle de Machine Learning, à partir des données que vous y intégrerez.
Ainsi, vous pourrez accomplir des tâches plus spécifiques. En outre, la console Google Cloud vous aide à configurer votre modèle sans avoir besoin de coder quoi que ce soit.
En conséquence, vous serez en mesure de choisir vos catégories de classification de texte, de personnaliser vos entités et d’adapter à votre domaine l’analyse des sentiments. Le processus d’utilisation s’effectue en quatre étapes :
- rassemblement des données en format CSV ou JSON dans un bac de stockage ;
- formation du modèle de Machine Learning ;
- évaluation de la précision de votre modèle (dont on ignore encore les principaux critères) ;
- déploiement, lequel ne prend que quelques minutes.
Évidemment, l’utilisation d’AutoML est plutôt réservée à des tâches plus délicates, pour lesquelles il vaut mieux développer un modèle personnalisé.
NLP et Google Natural Language API : un ensemble d’outils en voie de devenir indispensables
Doucement, mais sûrement, les logiciels et applications informatiques s’adaptent au langage naturel. La communication entre l’homme et la machine n’en est que plus fluide. En conséquence, la communication entre humains par l’intermédiaire de la machine se fluidifie aussi.
D’autre part, l’extraction et la simplification de l’information à partir de volumes textuels importants nous rend de plus en plus omniscients quant à nos activités : statistiques plus rapides et plus précises, tâches administratives automatisées, accès à l’essentiel d’un discours quel qu’il soit, etc.
Les NLP sont comme des extracteurs de jus, qui permettent d’obtenir en un temps record la substantifique moelle de vos documents !
Vos questions, nos réponses !
Qu’entend-on par API ?
Très grossièrement, les API (Application Programming Interface) les API sont des facilitateurs de communication entre plusieurs programme informatiques. Autrement dit, il s’agit d’un intermédiaire servant de support à l’échange et à la compréhension autonomes d’informations diverses entre deux machines. Ainsi, les API servent à configurer les interactions entre différents logiciels : quelles demandes, quelles réponses, sous quels formats et sous quel protocole, etc.
Par exemple, dans le cadre d’un paiement en ligne, l’API du site de e-commerce vient faire le médiateur. Il met en contact les coordonnées des comptes bancaires créditeurs et débiteurs, et assure du même coup la vérification de la sécurité de la transaction.
Puisque l’API consiste en une interface dédiée aux machines, l’utilisateur n’assiste pas aux détails de cette interaction très rapide ; il obtient simplement le résultat de sa demande. Bien pratiques, les API permettent donc d’ajouter des extensions aux fonctionnalités prédéfinies par une application.
À quoi peuvent servir les NLP concrètement ?
Toute information transmissible en format textuel (sans compter le langage naturel audio) est concernée par les NLP. Ainsi, vous pouvez analyser des conversations audio (idée très intéressante pour les tests utilisateurs), des documents scannés (reçus, factures, contrats), des avis d’internautes, etc.
Les meilleures performances à ce jour semblent revenir aux applications de traduction, aux chatbots et aux assistants personnels, qui présentent une compréhension plus fine du langage naturel.
Quelle est la différence entre Machine Learning et Deep Learning ?
Pour résumer, le Machine Learning se constitue d’algorithmes traitant de données structurées sous forme de valeurs numériques, afin d’en tirer des patterns. Le Deep Learning, en revanche, doit être capable de capter et d’identifier des informations sensorielles (son, images) et des données non structurées (textes, paroles).
Cette performance se rapprochant du cerveau humain lui vaut, mieux que tout autre outil, l’appellation d’intelligence artificielle.
Pourquoi peut-on également utiliser spaCy 101 ?
SpaCy 101 consiste en une autre manière d’utiliser des NLP. Il ne s’agit pas d’une API, ni d’une plateforme pour un service rapide. C’est une bibliothèque en open-source à partir de laquelle vous pouvez concevoir votre propre application de NLP.
Il vous sera d’une aide précieuse si vous codez sous Python un système d’extraction d’informations, d’analyse de langage naturel ou encore pour un prétraitement des textes préalable au Deep Learning. Un outil très performant et concurrentiel, pour peu que l’on s’y connaisse déjà.



