
Mis à jour le 06/05/2026
En informatique, le crawl, signifiant littéralement “ramper” en anglais, est l’action d’explorer un site web, page après page. On parle de crawl uniquement pour les algorithmes, et non pour les internautes, qui ne font que naviguer. À cet égard, une des principales différences réside dans la vitesse d’exécution ; le crawl ne nécessite qu’une infime fraction de seconde pour un bot.
Ainsi, les crawlers (ou spiders) sont des programmes spécialisés dans la visite ultra-rapide de sites web, ce qui permet aux moteurs de recherche de les analyser avant de les ranger dans leur index en récupérant leur code source. C’est donc une étape indispensable pour qu’un site web apparaisse dans les pages de résultats de recherche (ou SERP).
Nota Bene : il existe des logiciels de crawl à exploiter pour le référencement naturel et autres stratégies de présence digitale. googlebot
Quels sont les principaux types de crawlers ?
On peut distinguer trois grandes catégories de crawlers :
- les robots d’indexation (ou spiders) des moteurs de recherche, qui servent à l’indexation, l’évaluation et le ranking dans les SERPs. Les moteurs de recherche disposent chacun leur propre user agent : Googlebot pour Google et Bingbot pour Bing, l’outil de Microsoft, par exemple ;
- les crawlers de diagnostic, qui simulent le comportement d’un bot d’indexation, et que l’on peut lancer pour explorer n’importe quel domaine, à des fins d’analyse. Webmasters et experts en référencement en utilisent beaucoup pour détecter le moindre problème (contenu dupliqué, liens morts, pages inutiles, problèmes d’URL, etc.).
- les crawlers de veille tarifaire, qui permettent aux propriétaires de sites d’e-commerce de se tenir au courant de l’évolution du marché afin de moduler stratégiquement leur propre politique de prix en fonction de la concurrence. Certaines marketplaces en proposent aujourd’hui nativement sur leur plateforme.
Mais voyons un peu plus avant comment fonctionnent les spiders des moteurs de recherche !
Comment fonctionne un robot crawler de Google (ou autre) ?
Les crawlers d’indexation sont configurés pour passer et repasser en revue une énorme partie du World Wide Web, afin d’alimenter l’index du moteur de recherche qui les utilise. Ils vont déjà prioriser une partie des sites et pages à explorer en fonction de critères spécifiques. Ainsi, toutes les ressources du web ne sont pas crawlées avec la même assiduité.
Au cours de l’exploration, les bots vont sauvegarder les codes HTML des pages a priori les plus pertinentes pour les étudier ultérieurement. Ils retiennent également les liens hypertextes présents sur chaque site afin de voir vers quelles ressources pointent ces redirections, et si elles peuvent également avoir un intérêt pour les internautes.
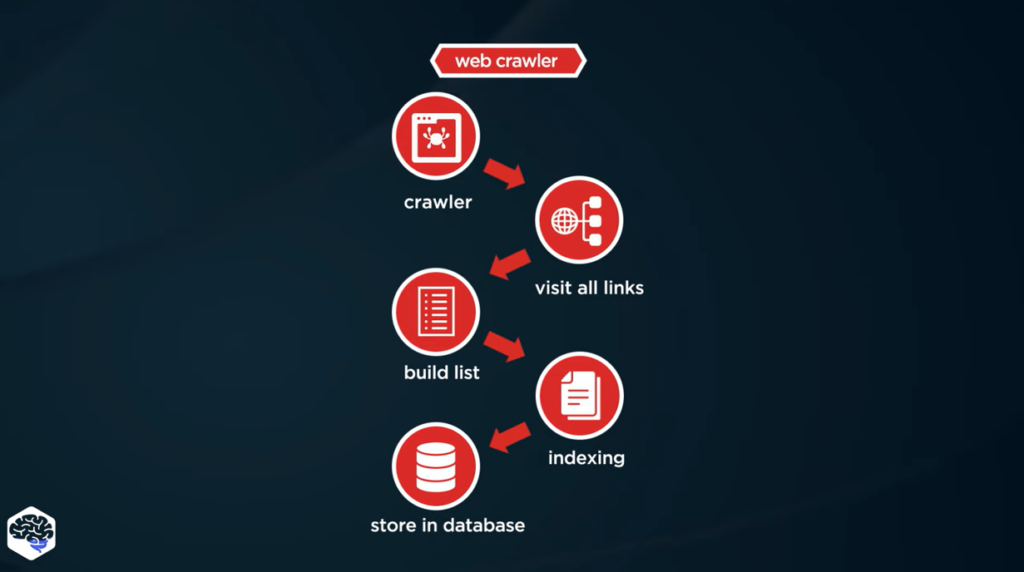
Une fois toutes les informations traitées, toutes les pages mémorisées vont intégrer l’index du moteur de recherche. Cette gigantesque archive sera alors prête à ressortir en suggestion, classées par ordre de pertinence, les URLs recueillies au moindre mot-clé saisi en barre de recherche et correspondant à leur contenu.
Et cela en continu en allant quotidiennement à la pêche aux mises à jour (nouvelle publication, refonte, etc.) sur l’ensemble des sites figurant dans l’index, afin de proposer aux visiteurs les pages web les plus fraîches possibles.
Combien de fois les spiders crawlent-ils mon site web ?
Pour obtenir cette information, il s’agit de procéder à une analyse de logs. Seulement, cette opération est relativement compliquée, qui requiert l’intervention d’un expert en référencement. Voici néanmoins quelques points à connaître pour y voir plus clair.
Le budget de crawl : ne pas l’épuiser inutilement !
Même s’il est surpuissant, le système algorithmique de Google comporte des limites. C’est pourquoi il attribue un budget crawl à chacun des sites, plus ou moins conséquent, notamment selon :
- sa note de pagerank interne ;
- son degré de popularité ;
- ses performances techniques (ex : vitesse de chargement) ;
- la profondeur des pages ;
- la fraîcheur des publications.
Peu importe le budget alloué à votre site web, il convient d’éviter de l’épuiser avec des pages inutiles (erreurs 404, duplicate content, contenus à faible valeur ajoutée et autres spider traps) ou orphelines (hors structure ou no match, c’est-à-dire qu’aucun chemin n’existe pour y accéder depuis la page d’accueil). Il peut s’agir de pages expirées ou provenant d’anciennes versions du site et mal redirigées, ou simplement d’URLs mal renseignées dans votre sitemap.
La fréquence de crawl : pas tous logés à la même enseigne !
La fréquence de crawl, c’est tout simplement le nombre de fois qu’un site est visité par les bots des moteurs de recherche sur une période donnée. Certaines pages très populaires vont pouvoir être crawlées plusieurs dizaines de fois par jour, tandis que d’autres ne verront pas le moindre bot pendant une semaine, voire davantage. À cet égard, Google utilise des critères fondés sur le comportement des utilisateurs pour voir quels contenus sur internet doivent faire l’objet de vérifications très régulières.
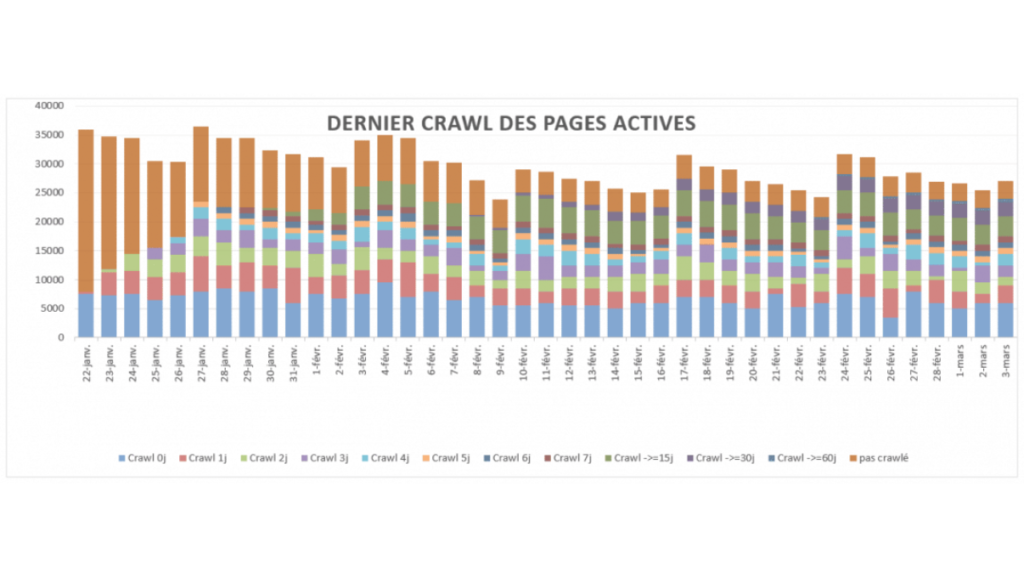
Nota Bene : la fenêtre de crawl est la fréquence de crawl requise pour qu’une page web devienne active, c’est-à-dire qu’elle accueille au moins un visiteur organique. Cette fenêtre dépend, bien entendu, de la popularité du site en question.
Crawl et SEO : en quoi les deux sont-ils liés ?
Le plus élémentaire à comprendre est que sans spider pour crawler une page web, nul indexation n’est possible. Et pas d’indexation, pas d’apparition dans les pages de résultats de recherche.
En second lieu il convient de se représenter que le crawl constitue déjà une première étape dans la classification, car c’est à ce moment que les bots peuvent observer :
- la structure de votre site web, et la cohérence dans l’arborescence des pages (et ce notamment à travers votre maillage interne) ;
- la profondeur de chaque page (qui correspond aux nombres de clics minimums nécessaire pour l’atteindre à partir de la page d’accueil, dont la profondeur est de facto 0) ;
- les liens hypertextes entrants (backlinks) et sortants vers d’autres sites, et la pertinence des ressources avec lesquelles votre site web est donc mis en relation ;
Or, ces trois points font partie des facteurs essentiels pour le ranking. Ainsi, lorsque vous organisez l’architecture de votre site web et que vous vous attelez à votre netlinking (maillage interne + stratégie de backlinks), gardez à l’esprit de vouloir fluidifier le travail des spiders, ne serait-ce que pour optimiser votre budget crawl, mais aussi potentiellement gagner de précieuses places dans les SERPs.
Utilisez vous-même des Crawlers pour votre référencement !
Bien sûr, plus votre site est grand, plus vous allez vous-même avoir besoin d’utiliser un crawler afin d’identifier toutes les problématiques à anticiper et à corriger pour fluidifier et le travail d’indexation en amont et, en aval, la navigation de vos visiteurs. Couplés à une analyse de logs, qui permet notamment de suivre l’activité des spiders de Google, de Bing, etc., vous aurez une vision complète de vos besoins SEO.
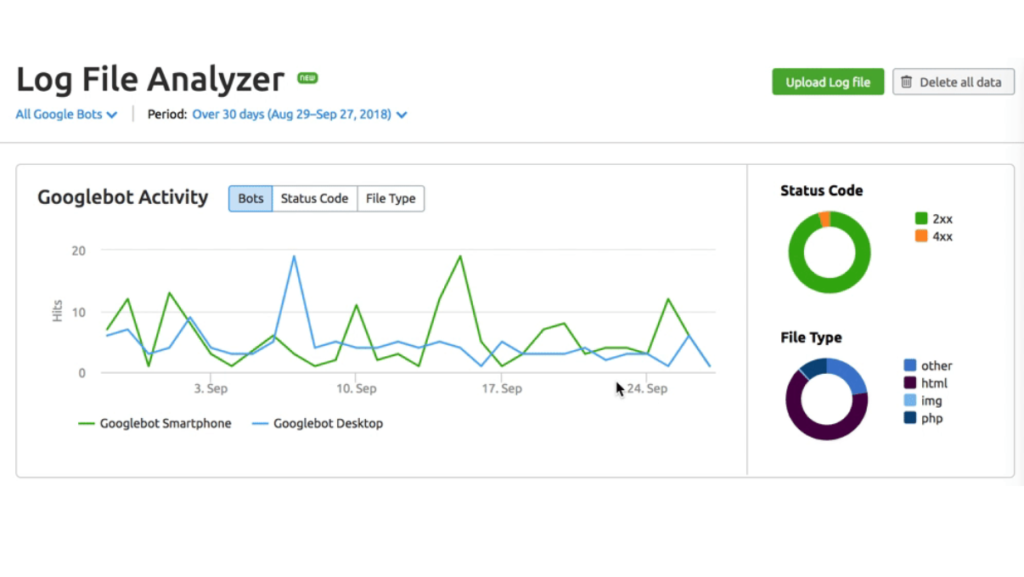
Nota Bene : ne pas confondre ces outils avec les “scrapers”, qui servent à extraire de la donnée d’un site web.
Quelques exemples de crawlers au service du SEO
Dans la catégorie des crawlers gratuits, on peut citer Xenu, LinkExaminer ou Free SEO Toolkit. Tous ont la capacité de vérifier vos backlinks, liens brisés, pages noindex ou redirections en no follow. Parfois, vous avez des fonctionnalités annexes comme le rapport sur la profondeur des pages, le poids de vos images, la détection de pages dupliquées, etc.
Quant aux crawlers payants, ils sont bien évidemment plus avancés. On recommandera sans hésiter :
- Screaming Frog vous laisse tester gratuitement 500 urls avant de vous facturer. Il permet l’audit complet de n’importe quel site web à extraire sur fichier Excel ;
- Deep crawl, spécialisé dans l’analyse approfondie de la qualité des backlinks avec des outils de mesure spécifiques ;
- SEMrush, particulièrement efficace en ce qui concerne la recherche de mots-clés, mais également trouver des opportunités de backlinks ;
- Botify permet de procéder à une analyse de logs ;
- Oncrawl également, qui présente ses rapports sous forme d’infographies plus lisibles que Screaming Frog ;
Pour finir…
Les crawlers représentent une dimension primordiale du web, dont dépend tout bonnement la visibilité d’une page auprès des internautes. Pour rendre une page attractive, il convient de respecter quelques pratiques fondamentales comme publier régulièrement du contenu qualitatif pour inciter au crawl, ficeler la structure d’un site via un maillage interne cohérent, augmenter ses backlinks de qualité, etc.
En outre, il sera rapidement indispensable de faire appel à un crawler indépendant des moteurs de recherche afin de nettoyer le site de toutes les erreurs qui peuvent ralentir les Googlebots ou les Bingbots… non sans vous faire accompagner par un consultant SEO !



